|
|
网络计算(In-Network Computing)是当前高性能计算和人工智能领域的前沿课题,它是InfiniBand网络面向新一代分布式并行计算体系结构,应用协同设计理念,开发出的一种通信加速技术。网络计算有效地解决了AI和HPC应用中的集合通信和点对点瓶颈问题,为数据中心的可扩展性提供了新的思路和方案。
它利用网卡、交换机等网络设备,在数据传输过程中,同时进行数据的在线计算,以达到降低通信延迟、提升整体计算效率等。成为和GPU和CPU同等重要的计算单元。
技术简介
在过去的几年,以云计算,大数据,HPC和AI等为代表的现代数据中心全面进化到分布式并行处理架构,数据中心的所有资源如CPU,内存,存储等分布在整个数据中心,使用高速网络技术把所有的资源连接起来,协同设计分工合作,共同完成数据中心的数据处理任务。在现代数据中心内,一切以业务数据为导向,构造均衡的系统体系架构,沿着业务数据流动的方向,CPU计算,GPU计算,存储计算,网络计算等各个部分合纵连横,分进合击,共同构成了以数据为核心的新一代数据中心系统架构。
作为连接现代数据中心所有资源的关键部件,以InfiniBand为代表的高速网络技术取得了突飞猛进的发展。随着1999年IBTA(InfiniBand Trade Association)组织成立并发布InfiniBand规范[1]后,InfiniBand高速网络技术得到快速发展并在HPC领域获得广泛的应用。如今在通向E级计算的道路上,网络计算技术正成为影响系统整体均衡的核心技术,成为分布式计算单元的一部分,协同CPU/GPU构建分布式计算池,协同存储构建分布式的内存池[2]。
作为高效的可扩展智能互连技术, InfiniBand将网络计算技术深入融入到产品实践中,实现无缝集成,通过网络计算解决通信瓶颈的问题,通过将各种通信相关的计算从CPU/GPU卸载到网络中来,将CPU和GPU的资源释放出来,让应用获得更多的计算资源,从整体应用的性能上得以提升,帮助企业应对数据挑战。
关键技术
1.网络协议卸载
提高数据的发送和接收性能一直是网络计算的基础。业界常见的TCP/IP协议栈,使用操作系统内核提供的软件实现协议栈的处理过程,需要大量挤占CPU的处理资源。在网络带宽越来越大,应用程序对性能要求越来越高的数据中心,越来越成为整体性能的瓶颈。
InfiniBand网卡和交换机通过ASIC硬件完整实现了网络通信的物理层、链路层、网络层和传输层,因此在通信过程中,数据流不需要额外的软件和CPU处理开销,极大地提高了通信性能。
2.远程直接内存访问(RDMA)
RDMA(Remote Direct Memory Access)是一种内核旁路技术,它提供了网卡硬件的抽象层verbs,运行用户空间的进程绕过内核直接访问RDMA网卡,实现高效快速通讯。RDMA源于InfiniBand网络技术,由IBTA组织对其进行标准化定义和维护。在硬件层面,RDMA硬件在发送和接收端双方向都通过DMA技术直接对用户态内存进行读写,通过使用网卡内置的网络协议卸载引擎,实现数据传输过程中的完整协议处理,在几乎不消耗CPU的情况下,实现高通量的网络通信。

3.GPUDirect RDMA
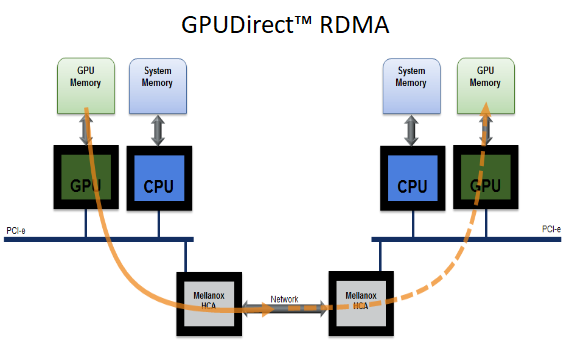
目前业界广泛使用GPU作为高性能计算或人工智能平台的计算核心,GPU之间的通信性能严重影响GPU机群的整体效率。GPUDirect技术把InfiniBand的RDMA能力应用到GPU节点之间的通信,加速GPU Cluster在HPC计算或AI训练过程中的GPU通信效率。它实现了RDMA网卡对GPU内存(GPU Memory)的直接读写,当GPU机群中两个节点GPU上的进程需要进行通信时,RDMA网卡可以在两边的GPU Memory之间直接实现RDMA数据搬移,消除了CPU对数据拷贝的参与,消除了不必要数据拷贝,减少了PCIe总线的访问次数,大幅提高了通信性能。
4.可扩展分层次聚合和归约协议(SHARP)
SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)是一种集合通信网络卸载技术。
在各种HPC和AI计中,常常有很多集合类通信,这些集合类通信由于涉及全局,常常对应用程序并行效率产生巨大的影响。业内有很多研究使用多种软件方法来优化聚合类通信的效率,但依然需要在网络中进行多次通信才能完成整体聚合操作,且很容易引入网络拥塞。与点对点通信对比,经过多种方法优化后,集合类通信的延迟仍然比点对点通信高一个数量级以上。
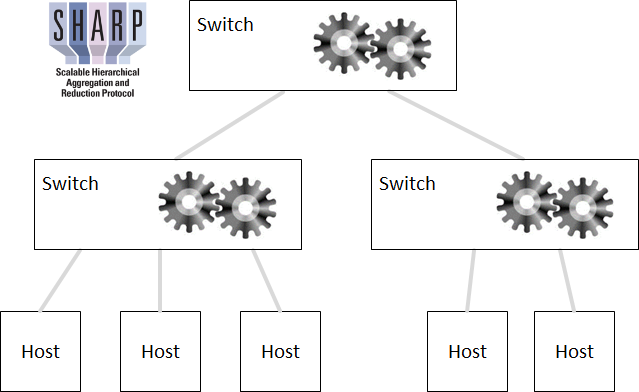
针对这种情况,NVIDIA Mellanox从EDR InfiniBand交换机开始引入了SHARP技术,在交换机芯片中集成了计算引擎单元,可以支持16位、32位及64位定点计算或浮点计算,可以支持求和,求最小值,求最大值,求与,求或及异或等计算,可以支持Barrier、Reduce、All-Reduce等操作。
在多交换机组成的机群环境下,Mellanox定义了一整套的可扩展分层次聚合和归约协议(SHARP)[3]卸载机制,由聚合管理器(Aggregation Manager)在物理拓扑中构造一个逻辑的SHARP树,由SHARP树中的多个交换机并行分布式处理集合类通信操作。当主机需要进行全局通信例如allreduce时,所有主机把通信数据提交到各自连接的交换机,第一级交换机收到数据后,会使用内置的引擎对数据进行计算和处理,然后把结果数据提交到SHARP树的上一级交换机,上一级交换机也使用自己的引擎对从若干个交换机收上来结果数据做聚合处理,并继续向SHARP树的上一级递交。到达SHARP树的根交换机后,根交换机做最后计算并把结果回发给所有的主机节点。通过SHARP方式,可以大幅降低集合通信的延迟,减少网络拥塞,并提升机群系统的可扩展性。
产品分类
- SHARPv1,在Switch-IB2 EDR InfiniBand上实现,最大支持256 Byte集合通信卸载
- SHARPv2,Quantum HDR InfiniBand上实现,最大支持2G Byte集合通信卸载
应用
高性能计算(HPC)
高性能计算领域大部分是计算密集型应用,计算过程中大量消耗CPU/GPU计算资源,且通常伴随着多种类型的点对点和集合通信,对通信的带宽、时延性能很敏感,需要通信协议卸载以减少CPU/GPU资源争抢,广泛应用了RDMA、GPUDirect及SHARP技术,提升整体计算性能。
人工智能(AI)
人工智能是目前最热点的技术之一,如何快速高效完成训练得到高准确率的模型是人工智能平台的关健技术之一。目前业界广泛使用GPU或专用AI芯片作为人工智能的训练平台计算核心以加速训练过程。人工智能训练也是典型的计算密集型应用,需要应用通信协议卸载以降低延迟。同时GPUDirect RDMA技术有效提升了GPU机群间的通信带宽,降低通信延迟。
大规模分布式训练中,目前比较流行的数据并行深度神经网络算法,需要利用多个神经网络并行训练,并在每个神经网络训练完一个迭代后,在所有神经网络之间进行模型同步。模型同步操作常常使用集合类通信例如all-reduce实现,其性能的好坏成为的成为影响分布式机器学习性能的关键因素。通过使用SHARP技术,可以明显提升AI训练的allreduce通信性能,加快通信模型同步过程,大幅提升机群的整体训练性能。
参考资料
[1] InfiniBand Trade Association, "InfiniBand Architecture Specification, Release 1.2," October 2004.
[2] Gil Bloch, Devendar Bureddy, Richard L. Graham, Gilad Shainer, and Brian Smith. 2017. Towards A Data Centric System Architecture: SHARP. Supercomputing Frontiers and Innovations: an International Journal, 4 (4), 416.
[3] R.L. Graham, D. Bureddy, P. Lui, "Scalable Hierarchical Aggregation Protocol (SHArP): A Hardware Architecture for Efficient Data Reduction", 2016 First International Workshop on Communication Optimizations in HPC (COMHPC), pp. 1-10, 2016. |
|



 发表于 2022-11-18 18:58:41
发表于 2022-11-18 18:58:41

