|
|
原文链接:从头开始实现一个神经网络
目录
- 神经网络的介绍
- 神经网络的组成
- 神经网络的工作原理
- Numpy 实现神经元
- Numpy 实现前向传播
- Numpy 实现一个可学习的神经网络
本篇文章非常适合初学者阅读,假设读者没有机器学习的基础。接下来将介绍神经网络的工作原理,如何用 Python 从头开始实现一个神经网络。
神经网络的介绍
神经网络受人类大脑启发的算法。简单来说,当你睁开眼睛时,你看到的物体叫做数据,再由你大脑中处理数据的 Nuerons(细胞)操作,识别出你所看到的物体,这是神经网络的工作过程。人工神经网络(Artificial Neural Network,ANN),它们不像你大脑中的神经元一样操作,而是模拟神经网络的性质和功能。
神经网络的组成
人工神经网络由大量高度相互关联的处理单元(神经元)协同工作来解决特定问题。首先介绍一种名为感知机的神经元。感知机接收若干个输入,每个输入对应一个权重值(可以看成常数),用它们做一些数学运算,然后产生一个输出。
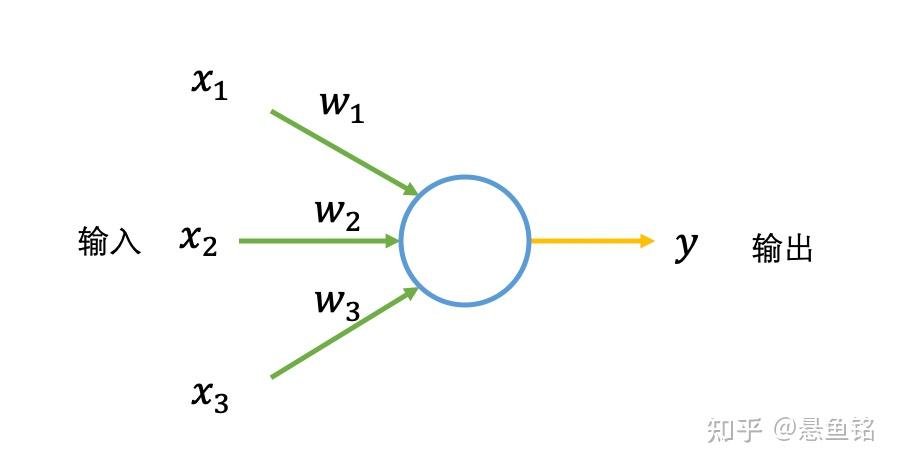
接下来用形象化的例子解释感知机,假设有一个计划,周末去徒步,影响计划是否进行的因素有这些:
(1)周末是否加班;
(2)周末的天气是否恶劣;
(3)往返徒步地点是否方便;
对于不同人,三个因素的影响效果也不一样,如果 输入(2)对于你来说影响非常大,这样就设置的权重值就大,反之权重值就小。
再将输入二值化,对于天气不恶劣,设置为 1(x_2=1),对于天气恶劣,设置为 0(x_2=0),天气的影响程度通过权重值体现,设置为 10(w_1=10)。同样设置输入(1)的权值为 8(w_2=8),输入(3)的权重值为 1(w_3=1)。输出二值化是去徒步为 1(y=1),不去为 0(y=0)。
假设对于感知机,如果 (x_1 \times w_1 + x_2 \times w_2 + x_3 \times w_3) 的结果大于某阈值(如 5),表示去徒步 y=1,随机调整权重,感知机的结果会不一样。
一个典型的神经网络有成百上千个神经元(感知机),排成一列的神经元也称为单元或是层,每一列的神经元会连接左右两边的神经元。感知机有输入和输出,对于神经网络是有输入单元与输出单元,在输入单元和输出单元之间是一层或多层称为隐藏单元。一个单元和另一个单元之间的联系用权重表示,权重可以是正数(如一个单元激发另一个单元) ,也可以是负数(如一个单元抑制或抑制另一个单元)。权重越高,一个单位对另一个单位的影响就越大。
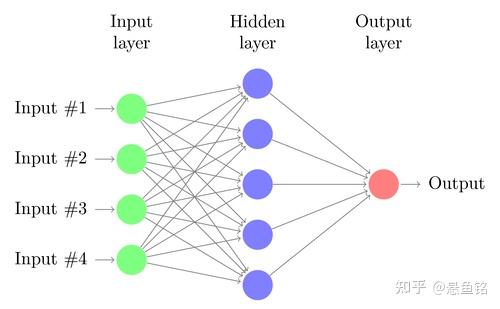
神经网络的工作原理
神经网络的工作大致可分为前向传播和反向传播,类比人们学习的过程,前向传播如读书期间,学生认真学习知识点,进行考试,获得自己对知识点的掌握程度;反向传播是学生获得考试成绩作为反馈,调整学习的侧重点。
以下展示了 2 个输入和 2 个输出的神经网络:
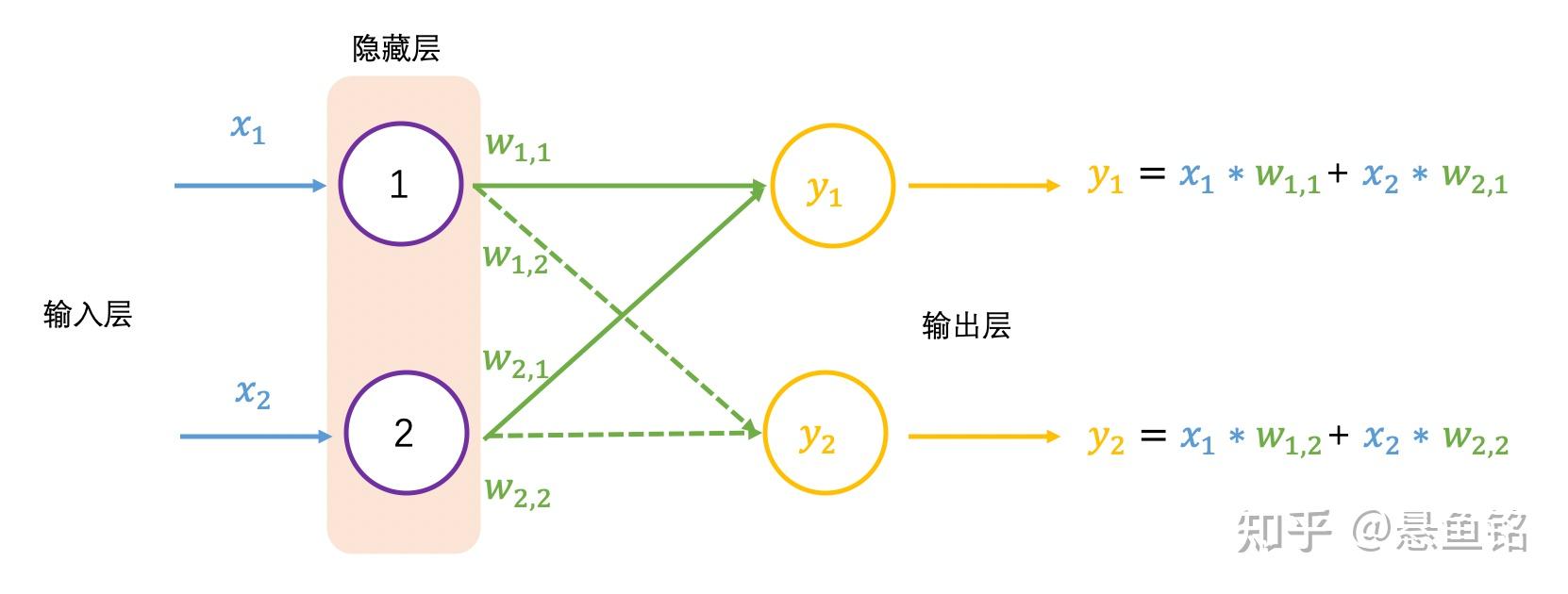
前向传播对应的输出为 y_1 和 y_2,换成矩阵表示为
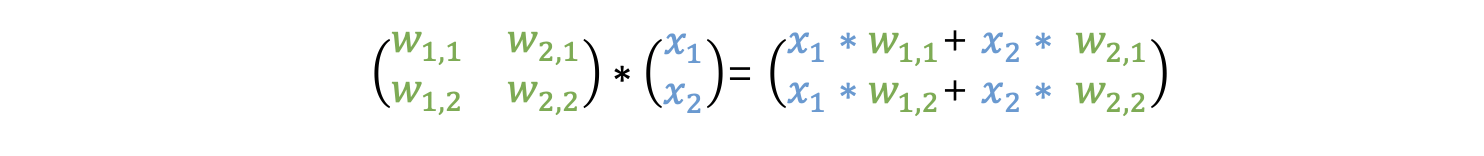
以上 W 矩阵每行数乘以 X 矩阵每列数是矩阵乘法,也称为点乘(dot product)或内积(inner product)。
继续增加一层隐藏层,如下图所示,并采用矩阵乘法表示输出结果,可以看到一系列线性的矩阵乘法,其实还是求解 4 个权重值,这个效果跟单层隐藏层的效果一样:
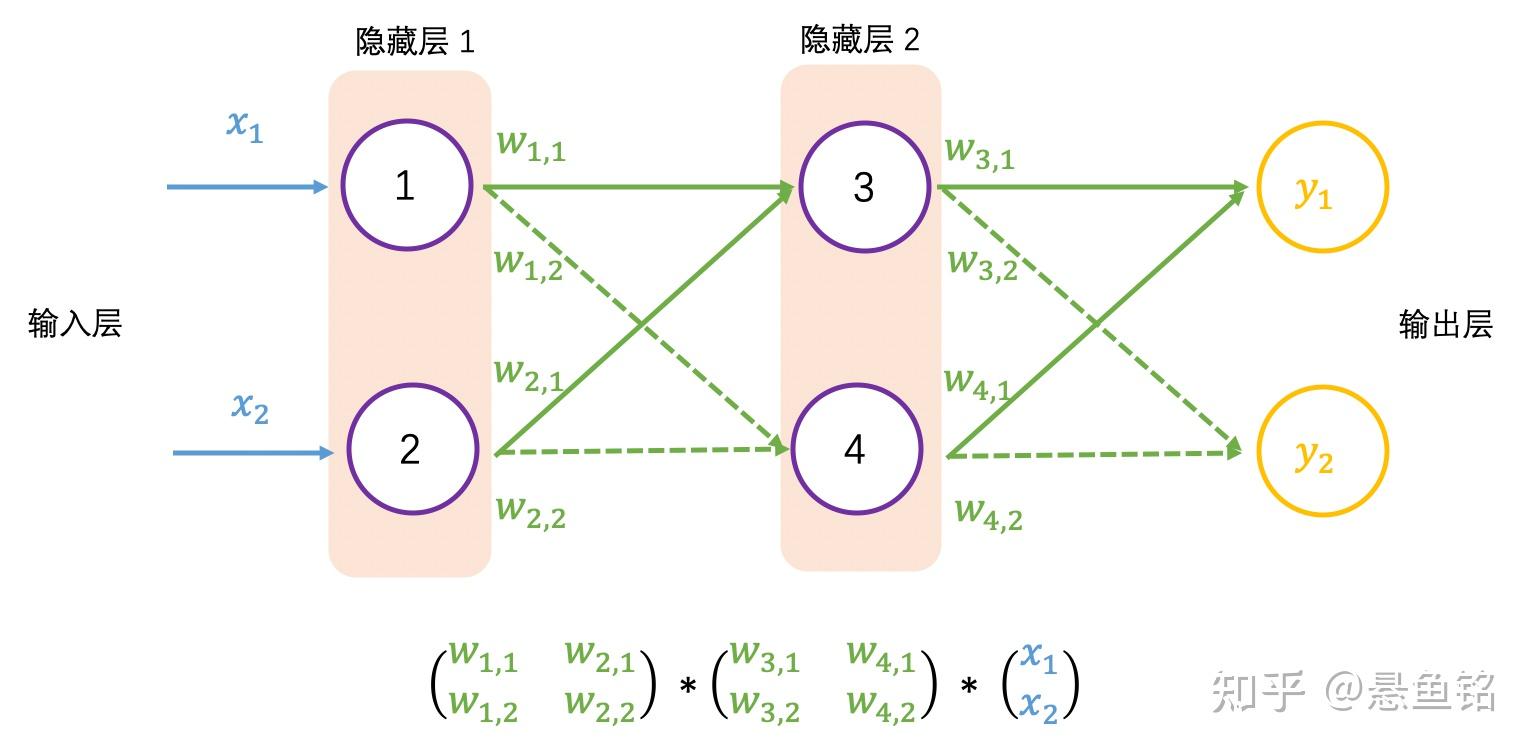
大多数真实世界的数据是非线性的,我们希望神经元学习这些非线性表示,可以通过激活函数将非线性引入神经元。例如徒步例子中的阈值,激活函数 ReLU(Rectified Linear Activation Function)的阈值为 0,对于大于 0 的输入,输出为输入值,对于小于 0 的输入值,输出为 0,公式和图像表示如下:
F (z) = max (0,z) \\
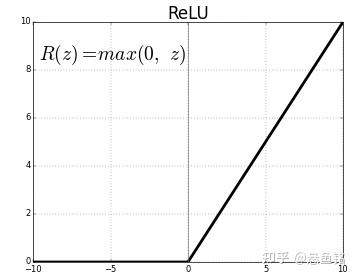
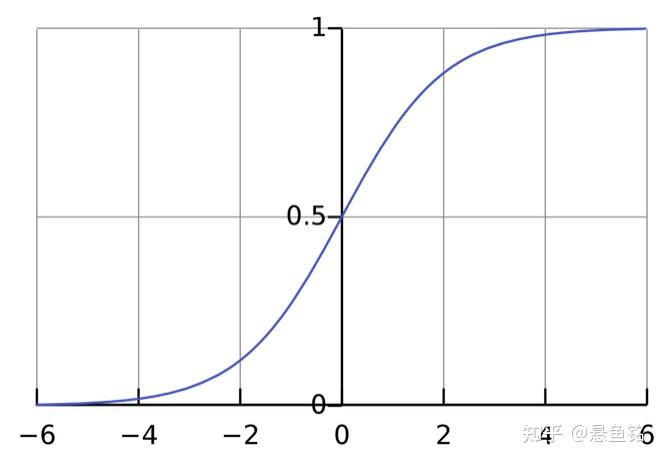
这里扩展一下,激活函数有很多种,例如常用的 sigmoid 激活函数,只输出范围内的数字 (0, 1),它将无界输入转换为具有良好、可预测的输出形式,sigmoid 函数的公式和图像如下。
f(x) = \frac{1}{1+e^{-x}} \\
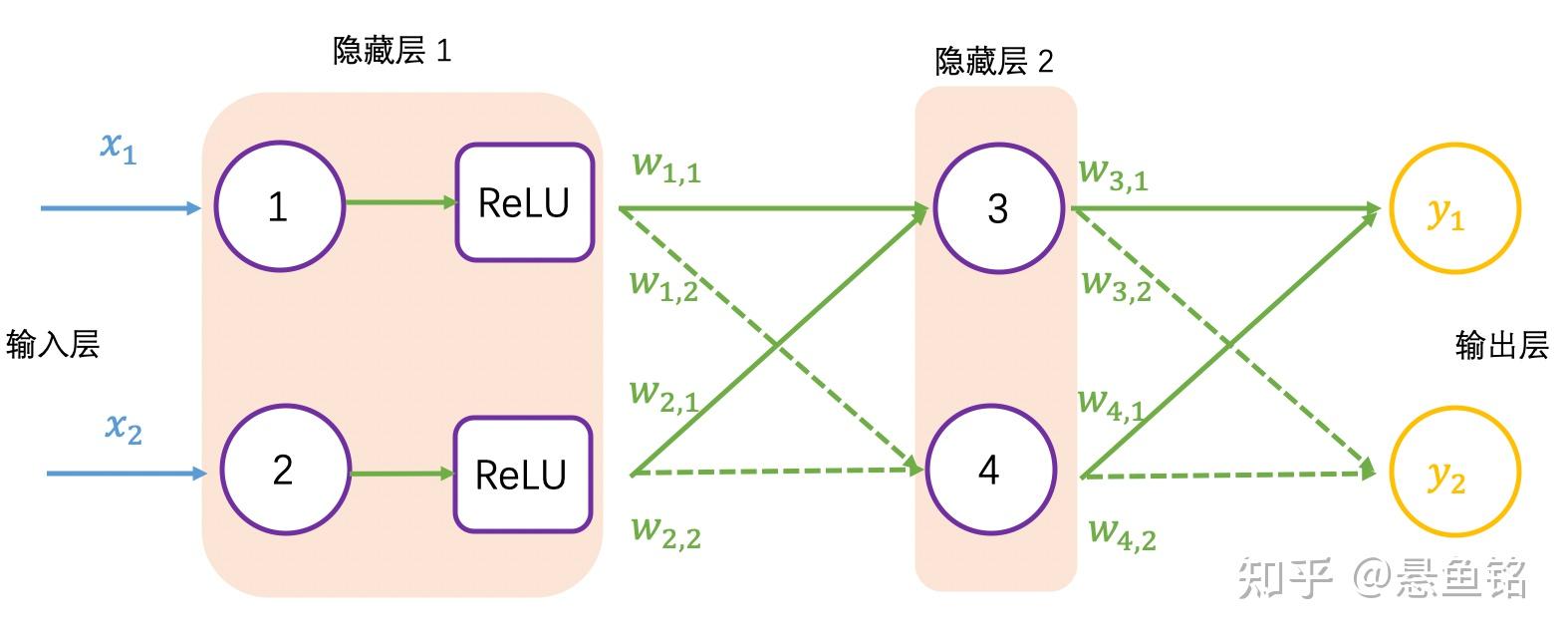
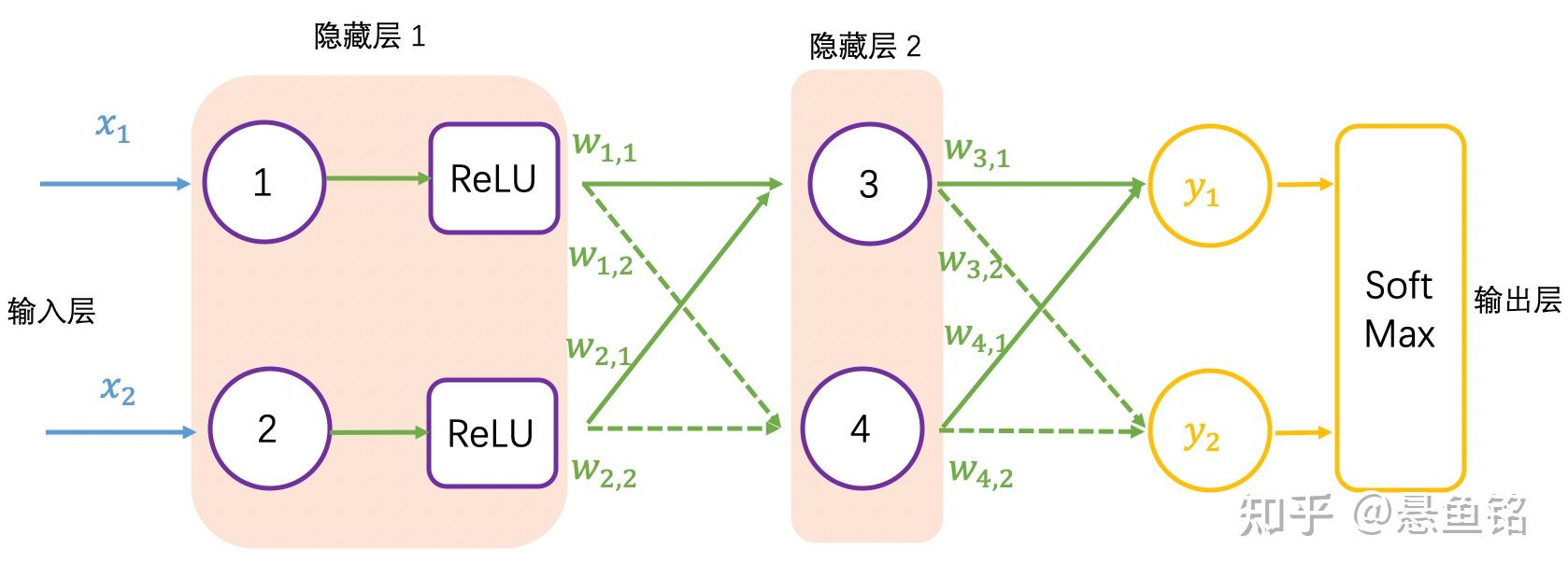
加入 ReLU 激活函数的神经网络如下图所示:
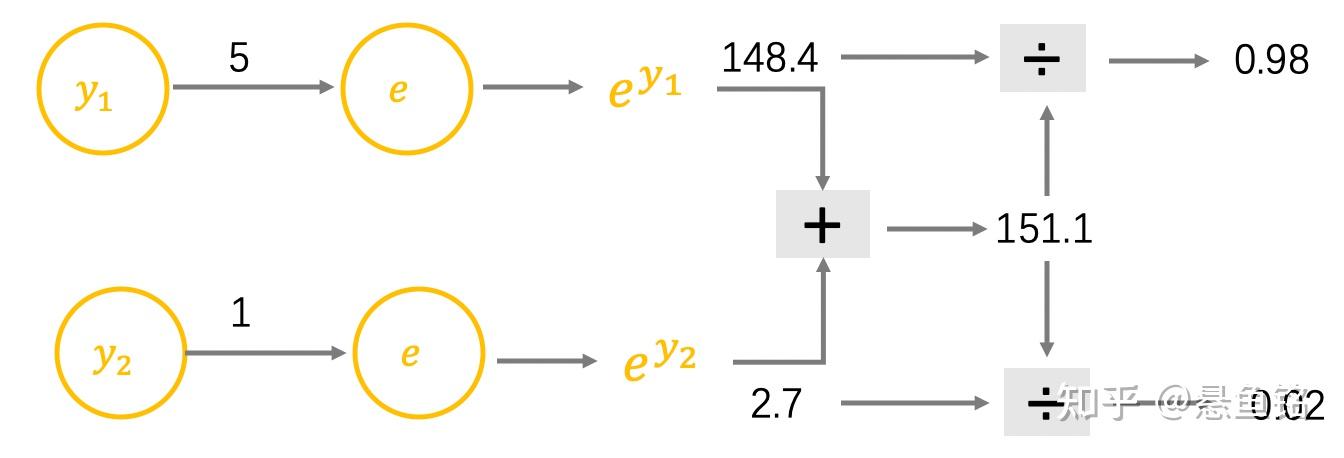
再以徒步为例,y_1=5 表示去徒步,y_2=1 表示不去徒步,在生活中会用概率表示徒步的可能性,用 SoftMax 函数调整输出值,公式如下。
SoftMax(y_{i})=\frac{e^{y_{i}}}{\sum_{c = 1}^{C}{e^{y_{c}}}} \\
y_1=5 和 y_2=1 的计算过程如下,可以看到徒步的概率是 98%:
加入 SoftMax 函数的神经网络如下图所示:
获得神经网络的输出值 (0.98, 0.02) 之后,与真实值 (1, 0) 比较,非常接近,仍然需要与真实值比较,计算差距(也称误差,用 e 表示),就跟摸底考试一样,查看学习的掌握程度,同样神经网络也要学习,让输出结果无限接近真实值,也就需要调整权重值,这里就需要反向传播了。
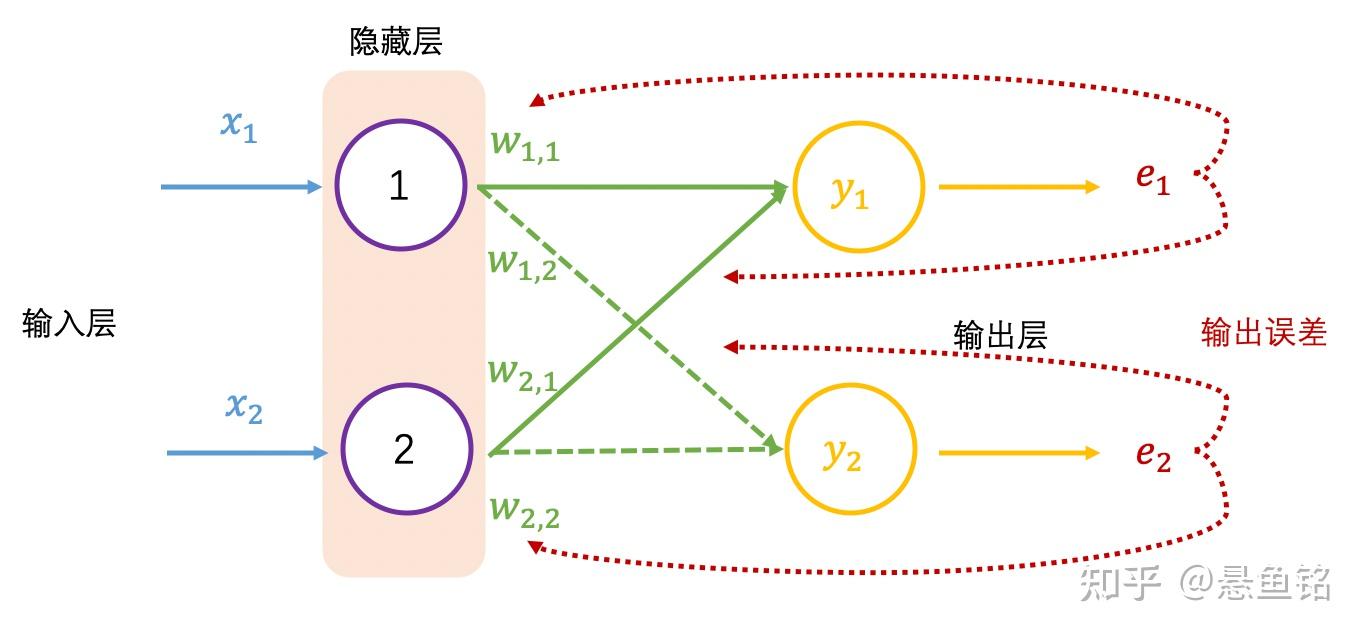
在反向传播过程中需要依据误差值来调整权重值,可以看成参数优化过程,简要过程是,先初始化权重值,再增加或减少权重值,查看误差是否最小,变小继续上一步相同操作,变大则上一步相反操作,调整权重后查看误差值,直至误差值变小且浮动不大。
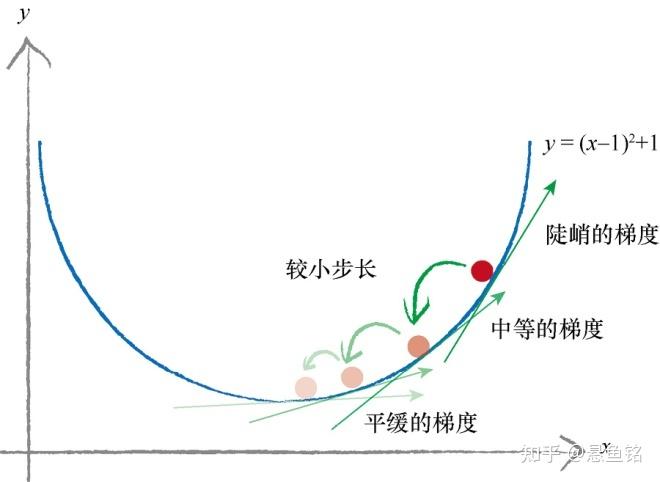
现在以简单的函数 y =(x-1)^2 + 1 为例,y 表示误差,我们希望找到 x,最小化 y,函数展示如下。红色点是随机的初始点类比权重值的初始化,左边是当 x 增大时,误差是减小;右边是当 x 减小时,误差是减小。如何找到误差下降的方向成为了关键。
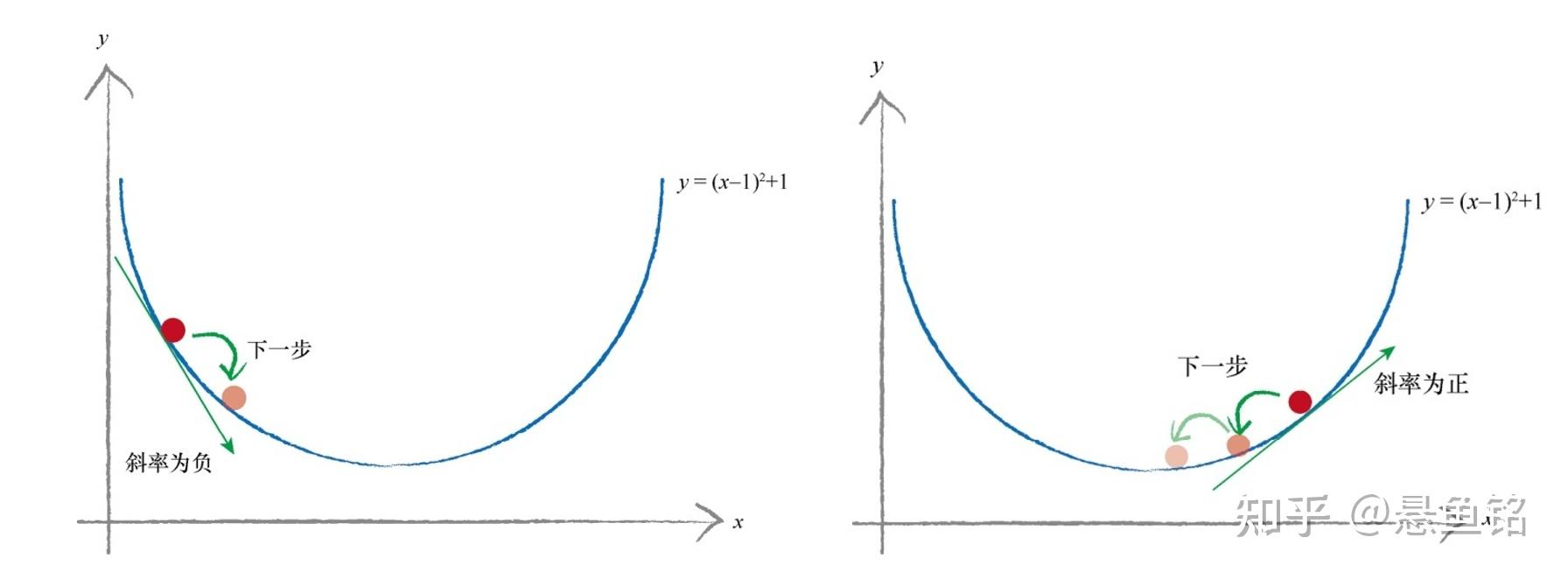
斜率的大小表明变化的速率,意思是当斜率比较大的情况下,权重 x 变化所引起的结果变化也大。把这个概念引入求最小化的问题上,以权重导数乘以一个系数作为权重更新的数值,这个系数我们叫它学习率 (learning rate),这个系数能在一定程度上控制权重自我更新,权重改变的方向与梯度方向相反,如下图所示,权重的更新公式如下:
W_{new} = W_{odd}-学习率*导数 \\
误差是目标值与实际输出值之间的差值,公式如下:
损失函数=(目标值-实际值)^2 \\
带入输入表示为:
MSE-Loss=(w \times x - y_{true})^2 \\
导数为:
(w*x-y)^{'}=2w*x^{2}-2x*y=2x(y-y_{true}) \\
经过反复迭代,让损失函数值无限接近 0,浮动不大时,获得合适的权重,即神经网络训练好了。
损失函数的Python实现代码如下。
import numpy as np
def mse-loss(y_true, y_pred):
# y_true and y_pred are numpy arrays of the same length.
return ((y_true - y_pred) ** 2).mean()
y_true = np.array([1, 0, 0, 1])
y_pred = np.array([0, 0, 0, 0])
print(mse_loss(y_true, y_pred)) # 0.5
Numpy 实现神经元
以上介绍了神经网络的基本结构及数学原理,为了方便大家理解,参数围绕着 W,后续继续深入学习,便遇到 b 参数(称为偏差),神经元会有以下这样的形式。
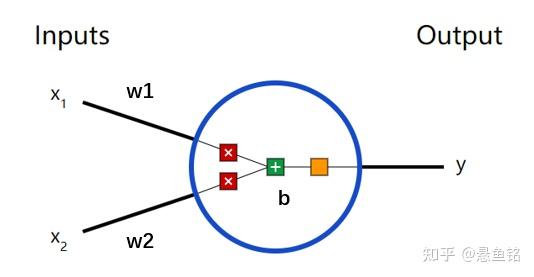
对于输入 x_1 和 x_2 有对应的权重值 w_1 和 w_2,两两相乘相加之后,还会加上一个参数 b,经过一个激活函数(记为f()),输出 y,表示如下:
y = f(x_1\times w_1+x_2\times w_2 +b) \\
用一个带入数字深入理解计算过程:
输入:x=[2,3],w=[0,1],b=4,使用 sigmoid 激活函数。
输出如下:
\begin{aligned} y = f(x_1\times w_1+x_2\times w_2 +b)\\ = f(2\times 0+ 3\times 1 +4) = f(7)\\ = \frac{1}{1+e^{-7}} \\ = 0.999 \end{aligned}\\
Python 代码实现如下:
import numpy as np
def sigmoid(x):
# Our activation function: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
class Neuron:
def __init__(self, weights, bias):
self.weights = weights
self.bias = bias
def feedforward(self, inputs):
# Weight inputs, add bias, then use the activation function
total = np.dot(self.weights, inputs) + self.bias
return sigmoid(total)
weights = np.array([0, 1]) # w1 = 0, w2 = 1
bias = 4 # b = 4
n = Neuron(weights, bias)
x = np.array([2, 3]) # x1 = 2, x2 = 3
print(n.feedforward(x)) # 0.9990889488055994
Numpy 实现前向传播
同样在神经网络中,如下图所示,这个网络有 2 个输入,一个隐藏层有 2 个神经元(h_1 和 h_2),和一个有 1 个神经元的输出层(o_1)。
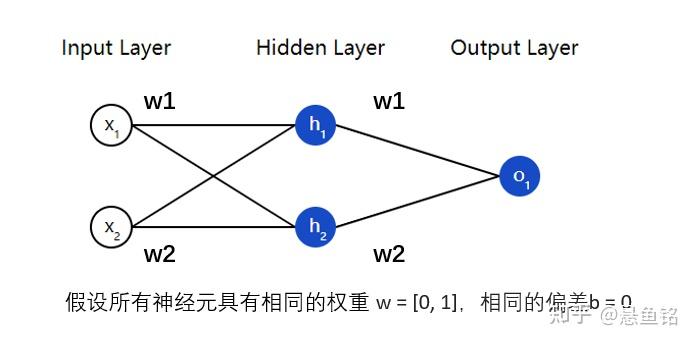
输入:x=[2,3],假设所有的神经元具有相同的权重 w=[0,1],相同的偏差 b=0,使用 sigmoid 激活函数。
输出如下:

Python 代码实现如下:
import numpy as np
class OurNeuralNetwork:
'''
A neural network with:
- 2 inputs
- a hidden layer with 2 neurons (h1, h2)
- an output layer with 1 neuron (o1)
Each neuron has the same weights and bias:
- w = [0, 1]
- b = 0
'''
def __init__(self):
weights = np.array([0, 1])
bias = 0
# The Neuron class here is from the previous section
self.h1 = Neuron(weights, bias)
self.h2 = Neuron(weights, bias)
self.o1 = Neuron(weights, bias)
def feedforward(self, x):
out_h1 = self.h1.feedforward(x)
out_h2 = self.h2.feedforward(x)
# The inputs for o1 are the outputs from h1 and h2
out_o1 = self.o1.feedforward(np.array([out_h1, out_h2]))
return out_o1
network = OurNeuralNetwork()
x = np.array([2, 3])
print(network.feedforward(x)) # 0.7216325609518421
Numpy 实现一个可学习的神经网络
终于到了实现一个完整的神经网络的时候了,把参数全安排上,别吓着了~
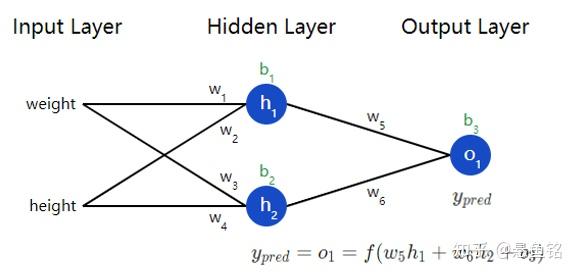
现在有一个明确的目标:最小化神经网络的损,将损失写成多变量函数,其中 =1。
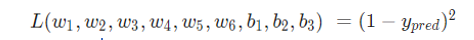
接下来数学公式有点多,别放弃~拿出笔和纸,一起写写!
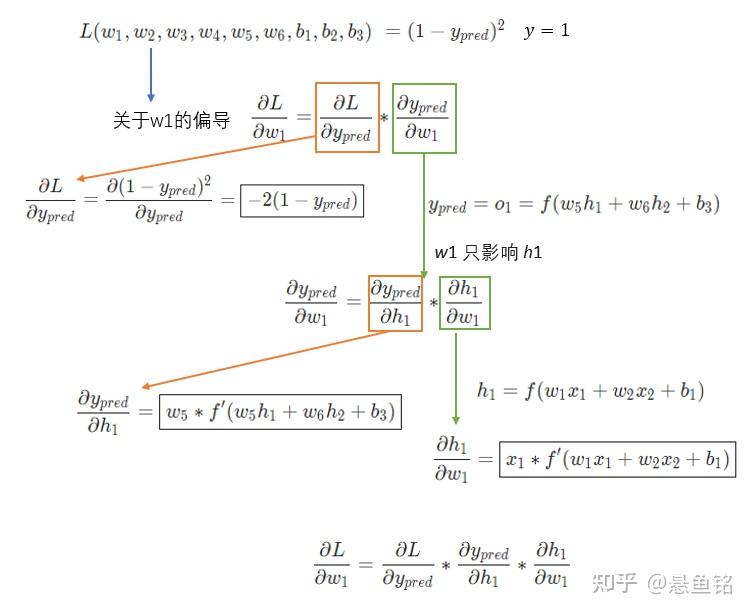
变量多的时候,求其中一个变量的导数时,成为求偏导数,接下来求 w_1 的偏导数,公式如下:
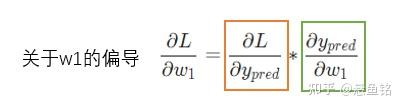
橙色框的内容关于损失函数可以直接得到:
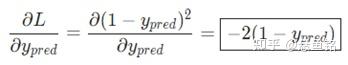
绿色框的内容,继续分析 y_{pred}:
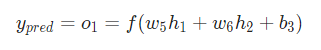
w_1 只影响 h_1 不影响 h_2,绿色框的内容拆解为:
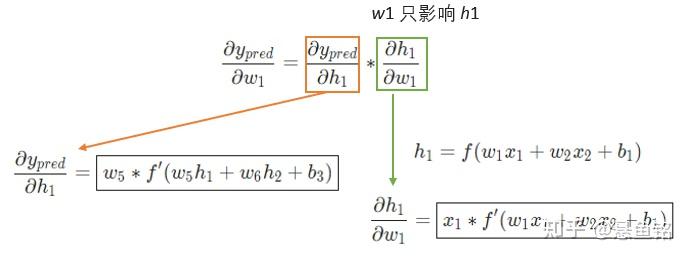
最终关于w_1 的偏导数,公式如下:
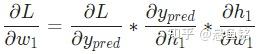
为了便于大家理解,将公式放在一起,请查阅~
这里会对 sigmoid 函数求导,求导的结果如下:
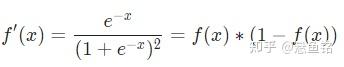
获得偏导数后,回忆一下参数的更新公式:
W_{new} = W_{odd}-学习率*偏导数 \\
- 如果偏导数为正,则参数减少;
- 如果偏导数为负,则参数增加。
如果我们对网络中的每个权重和偏差都这样做,损失将慢慢减少。
整个过程如下:
- 1.从我们的数据集中选择一个样本,进行操作
- 2.计算损失中关于权重和偏差的偏导数
- 3.使用更新公式更新每个权重和偏差
- 4.回到步骤1
Python 实现代码如下:
这里使用的数据集是 4 个样本,根据体重和身高预测性别(1 代表女性,0 代表男性),体重是数值 135 的偏差,身高是数值 66 的偏差。

import numpy as np
def sigmoid(x):
# Sigmoid activation function: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
def deriv_sigmoid(x):
# Derivative of sigmoid: f'(x) = f(x) * (1 - f(x))
fx = sigmoid(x)
return fx * (1 - fx)
def mse_loss(y_true, y_pred):
# y_true and y_pred are numpy arrays of the same length.
return ((y_true - y_pred) ** 2).mean()
class OurNeuralNetwork:
'''
A neural network with:
- 2 inputs
- a hidden layer with 2 neurons (h1, h2)
- an output layer with 1 neuron (o1)
*** DISCLAIMER ***:
The code below is intended to be simple and educational, NOT optimal.
Real neural net code looks nothing like this. DO NOT use this code.
Instead, read/run it to understand how this specific network works.
'''
def __init__(self):
# Weights
self.w1 = np.random.normal()
self.w2 = np.random.normal()
self.w3 = np.random.normal()
self.w4 = np.random.normal()
self.w5 = np.random.normal()
self.w6 = np.random.normal()
# Biases
self.b1 = np.random.normal()
self.b2 = np.random.normal()
self.b3 = np.random.normal()
def feedforward(self, x):
# x is a numpy array with 2 elements.
h1 = sigmoid(self.w1 * x[0] + self.w2 * x[1] + self.b1)
h2 = sigmoid(self.w3 * x[0] + self.w4 * x[1] + self.b2)
o1 = sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)
return o1
def train(self, data, all_y_trues):
'''
- data is a (n x 2) numpy array, n = # of samples in the dataset.
- all_y_trues is a numpy array with n elements.
Elements in all_y_trues correspond to those in data.
'''
learn_rate = 0.1
epochs = 1000 # number of times to loop through the entire dataset
for epoch in range(epochs):
for x, y_true in zip(data, all_y_trues):
# --- Do a feedforward (we'll need these values later)
sum_h1 = self.w1 * x[0] + self.w2 * x[1] + self.b1
h1 = sigmoid(sum_h1)
sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2
h2 = sigmoid(sum_h2)
sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3
o1 = sigmoid(sum_o1)
y_pred = o1
# --- Calculate partial derivatives.
# --- Naming: d_L_d_w1 represents "partial L / partial w1"
d_L_d_ypred = -2 * (y_true - y_pred)
# Neuron o1
d_ypred_d_w5 = h1 * deriv_sigmoid(sum_o1)
d_ypred_d_w6 = h2 * deriv_sigmoid(sum_o1)
d_ypred_d_b3 = deriv_sigmoid(sum_o1)
d_ypred_d_h1 = self.w5 * deriv_sigmoid(sum_o1)
d_ypred_d_h2 = self.w6 * deriv_sigmoid(sum_o1)
# Neuron h1
d_h1_d_w1 = x[0] * deriv_sigmoid(sum_h1)
d_h1_d_w2 = x[1] * deriv_sigmoid(sum_h1)
d_h1_d_b1 = deriv_sigmoid(sum_h1)
# Neuron h2
d_h2_d_w3 = x[0] * deriv_sigmoid(sum_h2)
d_h2_d_w4 = x[1] * deriv_sigmoid(sum_h2)
d_h2_d_b2 = deriv_sigmoid(sum_h2)
# --- Update weights and biases
# Neuron h1
self.w1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w1
self.w2 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w2
self.b1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_b1
# Neuron h2
self.w3 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w3
self.w4 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w4
self.b2 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_b2
# Neuron o1
self.w5 -= learn_rate * d_L_d_ypred * d_ypred_d_w5
self.w6 -= learn_rate * d_L_d_ypred * d_ypred_d_w6
self.b3 -= learn_rate * d_L_d_ypred * d_ypred_d_b3
# --- Calculate total loss at the end of each epoch
if epoch % 10 == 0:
y_preds = np.apply_along_axis(self.feedforward, 1, data)
loss = mse_loss(all_y_trues, y_preds)
print("Epoch %d loss: %.3f" % (epoch, loss))
# Define dataset
data = np.array([
[-2, -1], # Alice
[25, 6], # Bob
[17, 4], # Charlie
[-15, -6], # Diana
])
all_y_trues = np.array([
1, # Alice
0, # Bob
0, # Charlie
1, # Diana
])
# Train our neural network!
network = OurNeuralNetwork()
network.train(data, all_y_trues)
参考文献:
[1] https://github.com/vzhou842/neural-network-from-scratch
关注我,第一时间获取干货~ |
|



 发表于 2023-1-8 17:36:16
发表于 2023-1-8 17:36:16

