|
|
容器型数据类型:用一个变量可以保存多个数据
列表(list)
列表定义
在Python中,列表是由一系类元素按照特定顺序构成的数据序列,一个列表型的变量可以保存多个数据,允许有重复的数据,是一种结构化的、非标量类型。使用[]字面量语法来定义列表,元素用逗号进行分隔。
列表的切片
import random # 导入random文件
nums = [random.randrange(1, 100) for _ in range(9)]
# 在1-99的整数中水机筛选9个
print(nums[2:]) # 显示第3个数开始的后面所有的元素
print(nums[2: 7]) # 显示第3个到第7个元素
print(nums[:: -1]) # 把nums列表中的元素翻转显示
print(nums[3: 8: 2]) # 显示第3个到第8个步长为2的元素--->切片
语法 --- > list_obj[start: end: step] [开始: 结束: 步长]列表的相关操作
列表是可变类型,所以通过索引操作既可以获取列表中的元素,也可以更新列表中的元素。
# 创建列表的方式一:字面量语法
list1 = ['apple', 'orange', 'pitaya', 'durian']
print(list1)
# 创建列表的方式二:构造器语法
list2 = list(range(1, 10))
print(list2)
# 创建列表的方式三:生成式(推导式)语法
list3 = [i ** 2 for i in range(1, 10)]
print(list3)
# 获取列表元素的个数 ---- > len( )
print(len(list1))
print(len(list2))
# 遍历列表中的元素
for i in range(len(list1)):
print(list1)
for x in list1:
print(x)
for i, x in enumerate(list1):
print(i, x)
# 和列表相关的运算
list4 = [1, 10, 100] * 5 # 重复运算
print(list4)
print(10 in list4) # 成员运算 --- > in / not in ----> True / Flase
print(5 in list4)
# 索引和切片
# 正向索引:0 ~ N - 1 负向索引:- N ~ -1
print(list1[3])
print(list2[-7: -2: -1])
print(list2[2:])
# 合并
list5 = [1, 3, 5, 7]
list6 = [4, 4, 8]
list5 += list6
print(list5)
# 比较 ---- > 实际工作中使用较少,可以忽略不计
list7 = list(range(1, 8, 2))
list8 = [1, 3, 5, 7, 9]
print(list5 == list7)
print(list8 > list7)
for i in range(0x4e00, 0x9fa6):
print(chr(i), end='') # chr()函数 ----> 将编码处理成对应的字符(把编码变成字符)列表中常用函数
可以通过remove操作从列表中删除指定的元素
nums.remove(max_value) ----->通过remove操作从nums列表中删除max_value这个元素
列表的生成式语法(推导式)----> 写法简明,效率更高
例:nums = [random,randrange(1, 100) for _ in range(10)] # 在nums列表中生成一个随机数,并循环10次。
list() ---> list函数,构造器函数
创建列表的方式:字面量语法、构造器语法、生成式(推导式)语法
ord()函数 ---> 查看字符对应的编码(把字符变成编码)
insert() ---> 插入元素
clear() ----> 清空列表元素
index() -----> 在列表中找寻要求元素位置,返回下标
count() ---- > 统计一个元素在列表中出现的次数
del----> deliet ----> 删除一个对象的引用,作用类似于pop,性能优于pop,因为会返回删除的元素
del nums[0] # 删除nums列表中的第一个元素
extend()函数-----> 扩展一个列表
例: list6.extend(list5) 把列表5中的元素合并到列表6中
sample()函数----> random中的抽样函数,可以对列表元素进行无放回抽样
choices()函数 -----> random中的抽样函数, 可以对列表中的元素进行又放回抽样(可以重复抽中)
choice()函数 ----> random中的抽样函数,可以从列表中随机选择一个元素
shuffle()函数 ----> random中的抽样函数,可以实现列表元素的随机乱序
三元条件运算 -----> if后面的表达式为True,取if前面的值,否则取else后面的值
相当于简写版(精简版)的if.....else.....结构
元素排序和反转
reverse() ----- > 将列表中的元素反转排列
sort() ----> 将列表中的值按升序排序,可以通过reverse参数反转排降序
nums.sort(key = int) 把nums列表中的元素按整数的比较升序排列
例子:
import random
nums = [random.randrange(1, 1000) for _ in range(10)]
print(nums)
for i in range(len(nums) - 1):
# 假设第一个元素就是最小值
min_value, min_index = nums, i
# 通过循环找到有没有更小的值并记录下他的位置
for j in range(i + 1, len(nums)):
if nums[j] < min_value:
min_value = nums[j]
min_index = j
nums, nums[min_index] = nums[min_index], nums
print(nums)简单选择排序 - 每次从剩下的元素中选择
冒泡排序:元素两两比较,如果前面的元素大于后面的元素,就交换两个元素的位置
import random
nums = [random.randrange(1, 1000) for _ in range(10)]
print(nums)
for i in range(1, len(nums)):
swapped = False # swapped---->交换、对调
for j in range(0, len(nums) - i):
if nums[j] > nums[j + 1]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
swapped = True
if not swapped:
break
print(nums)列表的生成式(推导式)语法
例子: cards = [f&#39;{suite}{face}&#39; for suite in suites for face in faces]
例子:练习
&#34;&#34;&#34;
example01 - 嵌套列表
保存5个学生,3门课程的成绩
Author: Administrator
Date: 2021/7/27
&#34;&#34;&#34;
import random
names = [&#39;关羽&#39;, &#39;张飞&#39;, &#39;赵云&#39;, &#39;马超&#39;, &#39;黄忠&#39;]
courses = [&#39;语文&#39;, &#39;数学&#39;, &#39;英语&#39;]
scores = [[random.randrange(50, 101) for _ in range(len(courses))] for _ in range(len(names))]
# for i, name in enumerate(names):
# for j, course in enumerate(courses):
# print(f&#39;{name}的{course}成绩是: {scores[j]}&#39;)
print(scores)
# 统计每个学生的平均成绩
# for i, name in enumerate(names):
# total = 0
# for j, course in enumerate(courses):
# total += scores[j]
# mean_value = total / 3
# print(mean_value)
for i, name in enumerate(names):
print(f&#39;{name}的平均成绩是: {sum(scores) / len(courses): .1f}&#39;)
# 统计每门课的最高分和最低分
for j, course in enumerate(courses):
temp = [scores[j] for i in range(len(names))]
print(f&#39;{course}的最高分: {max(temp)}&#39;)
print(f&#39;{course}的最低分: {min(temp)}&#39;)EXCLE表格一些常用函数
=randbetween(50, 101) 生成随机数
=average(选择值) 求平均值
=max(选择值) 求最高分
=min(选择值) 求最低分
=stdev.p / stedev.s 求给的值的标准差
元组
(tuple)不可变的容器,(元组对象不支持给元素赋值的操作)如果是一元组的时候,后面必须跟上逗号,才是元组,否则就是普通的整数,一般用()来定义元组。
注意:一个元组中如果有两个元素,我们就称之为二元组;一个元组中如果五个元素,我们就称之为五元组。需要提醒大家注意的是,()表示空元组,但是如果元组中只有一个元素,需要加上一个逗号,否则()就不是代表元组的字面量语法,而是改变运算优先级的圆括号 元组的运算
例子: print(fruits * 3) 可以实现重复运算,但是得到的是一个新的元组,实际元组并没有变动
fruits1 = (&#39;apple&#39;, &#39;banana&#39;, &#39;grape&#39;)
print(fruits1 * 3) # 重复运算,得到一个新的元组,原元组不变
print(&#39;grape&#39; in fruits1) # 成员运算,得到布尔值
print(&#39;apple&#39; not in fruits1)
fruits2 = (&#39;litchi&#39;, &#39;orange&#39;)
fruits3 = fruits2 + fruits1 # 合并运算,fruits2和fruits1并没有变动,
只是得到一个新的元组
print(fruits3)
print(fruits3[1: 4]) # 元组的切片,读取第二个元素到第四个元素
print(fruits3[:: -1]) # 元组的反转
print(fruits3[1: 4: 2])
print(fruits1.index(&#39;banana&#39;))
print(fruits1.count(&#39;banana&#39;))元组的应用
unpack ----> 解包:把一个元组拆成多个元素
ROTATE-----:交换:交换2个值或者交换3个值
在解包时,如果解包出来的元素个数和变量个数不对应,会引发ValueError异常,有一种解决变量个数少于元素的个数方法,就是使用星号表达式,有了星号表达式,我们就可以让一个变量接收多个值。
** 星号表达式修饰的变量会变成一个列表,列表中有0个或多个元素。还有在解包语法中,星号表达式只能出现一次。 a, b, *c = 5, 15 # C赋空值
print(a)
print(b)
print(c)
a, *b, c = 4, 7, 9 ,10, 15 # a = 第一个元素,c = 最后一个元素,中间其他的都打包给b
print(a)
print(b)
print(c)字符串
(str)由零个或者多个字符组成的有限序列
转义字符----> / (反斜杠)
\t------->生成制表键
\n------> 折行
\b ---------> 退格
\------> 两个\才能表示路径的\
\a ---------> 报警
a = &#39;\&#39;hello, \t word\b\b \&#39;&#39;
b = &#34;\&#34;hello, \n \n word\&#34;&#34;
c = &#39;&#39;&#39;
飞流直下三千尺,
疑是银河落九天。
&#39;&#39;&#39;
print(a)
print(b)
print(c)原始字符串
在字符串前面加r或者R,没有转义字符,每个字符都是原始的含义
格式化字符串:在字符串前面加f,就是格式化处理字符串,带占位符的字符串
\u------>Unicode(万国码)-----> 字符集,UTF-8编码(Unicode的一种实现方案),支持国际化 字符串的运算
字符串也是不变数据类型,只能进行读操作,不能进行写操作
重复运算:
# 重复运算
print(a * 5)成员运算:in和not in判断一个字符串中是否存在另外一个字符或字符串,in和not in运算通常称为成员运算,会产生布尔值True或False。
比较运算:(比较字符串的内容 -----> 字符编码大小)
len(a) ----> 获取字符串a的长度
循环变量字符串每个字符:两种方法
# 循环遍历字符串每个字符
for i in range(len(a)):
print(a)
for i in a:
print(i)清楚屏幕输出:Windows ---->cls / macPS ----> clear
字符串的操作
温馨提示:Str类型是不可变类型 字符串中一些常用方法
用变量名.方法名()的方式来调用,也可以说是某个类型的变量绑定的函数
upper() ----> 把字符串全部转成大写
lower() ------>把字符串全部转成小写
capitalize() ------> 把字符串首字母转成大写
title() ------> 把每个单词首字母大写
isdigit() ----> 判断字符串是否由数字构成
isalpha() -----> 判断字符串是否由字母构成
isalnum() --------> 判断字符串是否由数字和字母构成
isascii() -------> 判断字符串是否是由ASCII码构成的字符,Python 3.7中添加的一个方法
startswith------> 判断字符串是否以指定内容开头
endswith ------> 判断字符串是否以指定内容结尾
a = &#39;i Name is&#39;
print(a.upper()) # 把字符串全部转成大写
print(a.lower()) # 把字符串全部转成小写
print(a.capitalize()) # 把字符串首字母转成大写
print(a.title()) 把每个单词首字母大写
b = &#39;123abc&#39;
print(b.isdigit()) # 判断字符串是否由数字构成
print(b.isalpha()) # 判断字符串是否由字母构成
print(b.isalnum()) # 判断字符串是否由数字和字母构成
print(b.isascii()) # 判断字符串是否是由ASCII码构成的字符
c = &#39;你好啊,地球&#39;
print(c.isascii())
print(c.startswith(&#39;你&#39;)) # 判断字符串是否以指定内容开头
print(c.endswith(&#39;地&#39;)) # 判断字符串是否以指定内容结尾在字符串中查找有没有某个子串的操作
~ index / rindex
~ find / rfind
index()-----> 从左向右寻找指定的子串,可以指定从哪开始找,值默认是0,找到了返回子串对应的索引(下标),找不到直接报错(程序崩溃)
rindex() ----> 从右向左寻找
find() ------>从左向右寻找指定的子串,可以指定从哪开始找,值默认是0,找到了返回子串对应的索引(下标),找不到程序返回-1.
system()函数------> 调用系统命令
所有操作系统都用os模块导入
格式化字符串:
center()函数----->居中
rjust()函数------> 右对齐
ljust()函数------->左对齐
zfill()函数----> 零填充,在左边补0
a = &#39; hello, word &#39;
print(a.center(80, &#39;-&#39;))
print(a.rjust(80, &#39;~&#39;))
print(a.ljust(80))
b = &#39;123&#39;
print(b.zfill(8))
c = 1234
d = 456
print(&#39;%d + %d +%d&#39; % (c, d, c + d))
print(f&#39;{c} + {d} = {c + d}&#39;)
print(&#39;{} + {} = {}&#39; .format(c, d, c + d))
print(&#39;{0} + {1} = {2}&#39; .format(c, d, c + d))
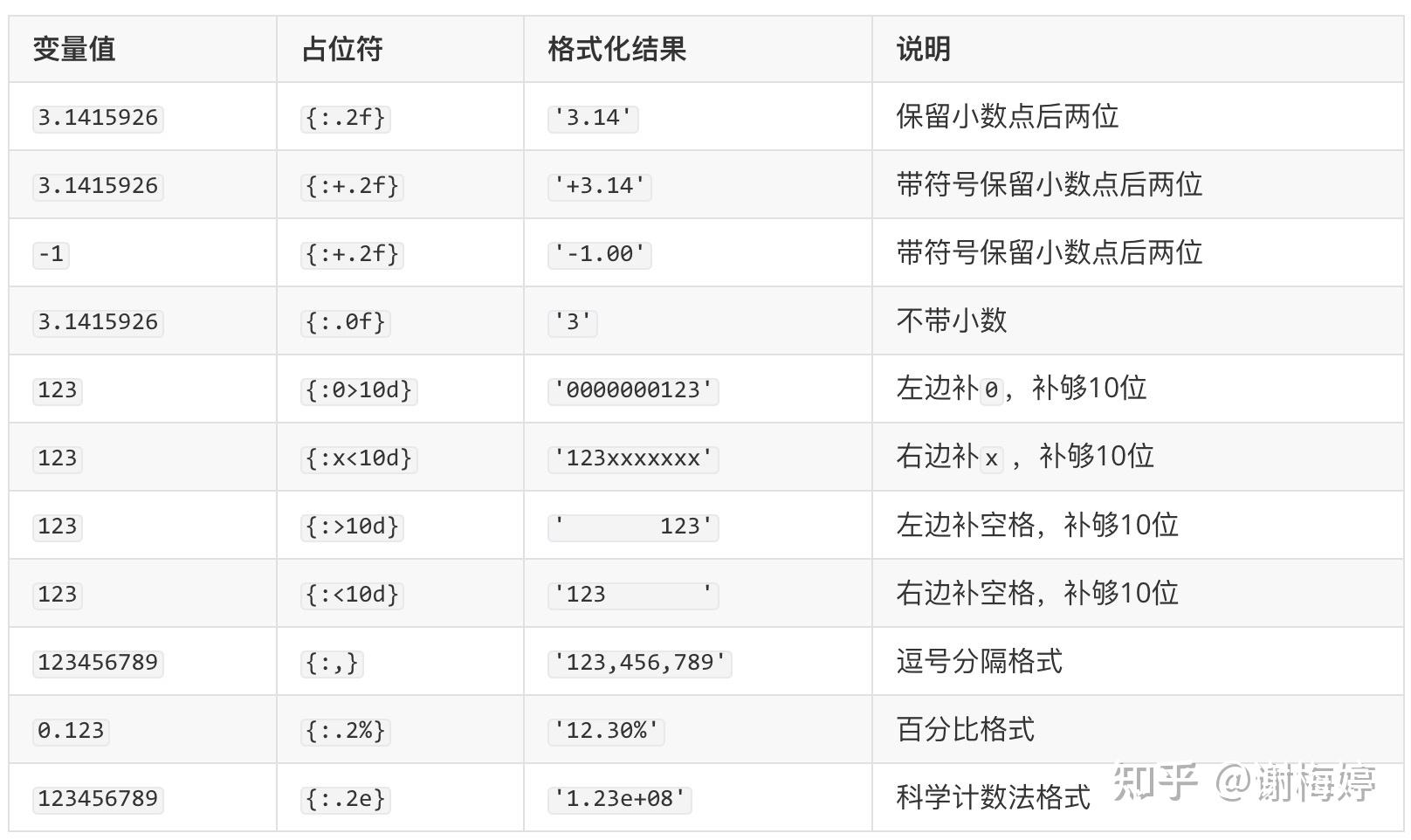
如果需要进一步控制格式化语法中变量值的形式,可以参照下面的表格来进行字符串格式化操作。
strip()函数----> 修剪字符串左右两端的空格
lstrip()函数----> 修剪字符串左端的空格
rstrip()函数 -----> 修剪字符串右端的空格
####字符串的替换:
replace()函数 -------> 替换函数----->将指定的字符串替换为新的内容
email = &#39; python3.8@168.com&#39;
content = &#39; 马化腾是大傻逼 &#39;
print(email.strip())
print(email.lstrip())
print(content.rstrip())
print(content.strip().replace(&#39;马化腾&#39;, &#39;*&#39;).replace(&#39;傻逼&#39;, &#39;*&#39;))字符串的拆分和合并:
split()函数----> 拆分,用空格拆分字符串得到一个列表
maxsplit-----> 指定最大拆分次数
rsplit()函数 ------> 从右向左进行字符串的拆分
&#39; &#39;.join()函数 ----> 将列表元素进行合并,变成一个字符串
content = &#39;to be not to be , you up&#39;
# 用空格拆分一个字符串得到列表
words = content.split()
print(words, len(words))
for word in words:
print(word)
# 用空格拆分字符串,最多允许拆分4次
words = content.split(&#39; &#39;, maxsplit=4)
print(words, len(words))
# 从右向左拆分字符串,最多允许拆分3次
words = content.rsplit(&#39; &#39;, maxsplit=3)
print(words, len(words))
# 用逗号拆分字符串
items = content.split(&#39;,&#39;)
for item in items:
print(item)
contents = [
&#39;床前明月光&#39;,
&#39;疑是地上霜&#39;,
&#39;举头望明月&#39;,
&#39;低头思故乡&#39;
]
# 将列表中的元素用指定字符串连接起来
print(&#39;/&#39;.join(contents))编码:把一种字符集映射(转换)成另外一种字符集
解码:
encode()函数----> 用于编码-----> 不填的时候默认是万国码(UTF-8)的一种实现方案,把字符串转换成字节串
decode()函数 ----> 用于解码------> 把字节串转换成字符串
GBK中一个汉字对应两个字节,UTF-8中认为一个汉字对应三个字节
编码和解码的方式一定要统一,如果编码和解码的方式不一致,Python中通常会产生异常,也有可能会出现乱码现象
iso - 8859 - 1 :拉丁语系列码,不能用来处理中文字符,会产生编码黑洞,中文全部变成?,想解码也没有机会
UTF-8是一种变长编码,表示数字和英文字母的时候,只需要一个字节,表示Emojie字符的时候是四个字节
要点:
1, 选择字符集(编码)的时候,最佳的选择(也是默认值)是UTF-8编码。
2, 编码和解码的字符集要保持一致,否则就会出现乱码现象。
3, 不能用ISO-8859-1编码保存中文,否则会出现编码黑洞,中文变成?。
4, UTF-8是Unicode的一种实现方案,也是一种变长的编码。 延伸
凯撒密码:通过对应字符的替换,实现对明文进行加密的一种方式
对称加密:加密和解密使用了相同的密钥。
非对称加密:加密和解密使用不同的密钥(公钥、私钥) -----> 适合互联网应用。
maketrans()函数 ------> 字符串中的生成字符串转换的对照表
translate()函数 ------> 通过字符串的translate方法实现转译
message = &#39;attack at dawn&#39;
table = str.maketrans(&#39;abcdefghijklmnopqrstuvwxyz&#39;,
&#39;defghijklmnopqrstuvwxyzabc&#39;)
print(message.translate(table))random.choices()函数 -------> random模块下choices()函数,有范围抽样
string模块中,ascii_letters大小写字母,digits1-9数字
import random
import string
all_chars = string.ascii_letters + string.digits
for _ in range(5):
# 可迭代对象
call = random.choices(all_chars, k=4)
print(&#39;&#39;.join(call))集合
(set)把一定范围的、确定的、可以区别的事物当作一个整体来看,用{}
特性:
无序性:一个集合中,每个元素的地位都是相同的,元素之间是无序的。
互异性:一个集合中,任何两个元素都认为是不相同的,即每个元素只能出现一次。
确定性:给定一个集合,任给一个元素,该元素或者属于或者不属于该集合,二者必居其一,不允许有模棱两可的情况出现。 set1 = {1, 1, 2, 3, 1, 1, 2}
print(type(set1), len(set1))
# 互异性,没有重复元素
print(set1)
set2 = set()
print(type(set2), len(set2))
# 遍历集合中的元素
for emle in set1:
print(emle)集合的运算
一般情况,在效率上远远高于列表的成员运算
运算符
&:用这个符号求两个集合的交集
| :用这个符号求两个集合的并集
差集:我有你没有的
^ :用来求两个集合的对称差,或者并集减交集也是对称差
< : 判断真子集
<= :判断子集
>:判断超集
set1 = {1, 2, 4, 7, 9}
set2 = {2, 4, 6, 8}
# 成员运算 - 确定性(元素要么在集合中,要么不在集合中)
print(1 in set1)
print(1 not in set1)
# 交集
print(set1 & set2)
print(set1.intersection(set2))
# 并集
print(set1 | set2)
print(set1.union(set2))
# 差集 我有你没有
print(set1 - set2) # 得到set1有set2没有的集合
print(set2 - set1) # 得到set2有set1没有的集合
print(set1.difference(set2)) # 得到set1有set2没有的集合
print(set2.difference(set1)) # 得到set2有set1没有的集合
# 对称差
print(set1 ^ set2)
print((set1 | set2) - (set1 & set2)) # set1和set2的并集减交集也是对称差
print(set1.symmetric_difference(set2))
set3 = {1, 2, 3, 4, 5, 6, 7, 8, 9}
# 判断真子集
print(set1 < set3) # set1是set3的真子集
# 判断子集
print(set1 <= set3) # set1是set3的子集
# 判断超集
print(set3 > set2) # set3是set2的超集集合的操作(方法)
集合里面可以放元组,字符串,布尔值等等,但是不能放列表
哈希存储:哈希函数----> hash()----> 哈希码/散列码
哈希冲突:
1、 集合底层使用哈希存储(高效率的存储方案)
2、 哈希存储的关键是设计一个好的哈希函数,让不同的对象尽可能的产生不同的哈希码
3 、集合在元素查找是效率远高于列表(因为集合是哈希存储而列表是顺序存储),不依赖问题的规模,是一种常量级时间复杂度的存储方案
4、 如果一个对象无法计算哈希码,就不能放到集合中,列表就是无法计算哈希码的对象
** 可变容器(列表、集合、字典)**都无法计算哈希码,因此都不能放到集合中,去作为集合中的元素。
集合中加元素用add()函数,删除用pop()函数,因为无序性,删除谁随缘,不过discard()函数可以指定元素删除,清空元素用clear()函数
set1 = {&#39;apple&#39;, &#39;orange&#39;, &#39;pitaya&#39;, &#39;apple&#39;}
# 添加元素
set1.add(&#39;banana&#39;)
set1.add(&#39;durian&#39;)
print(set1)
# 删除元素
set1.discard(&#39;pitaya&#39;)
print(set1.pop())
print(set1.pop())
print(set1)
# 清空元素
set1.clear()
print(set1)
# 列表、集合和元组的相互转换
nums = [1, 3, 5, 7, 9, 1, 3, 1, 9, 7]
set2 = set(nums)
print(set2)
list2 = list(set2)
print(list2)
tuple3 = tuple(list2)
print(tuple3)
set4 = set(&#39;hello&#39;)
print(set4) 字典
(dict)元素由键和值两部分构成,冒号前面的称为键,冒号后面的称为值,合在一起叫键值对。
字典的建必须是不可变的数据类型,直接花括号是空字典 dict()---->字典的构造器函数
字典的创建方式:
_.keys()函数 ----> 遍历字典中的键
_.values()函数----->遍历字典中的值
_.items()函数------->遍历字典中的键值对
# 字面量语法
student1 = {
&#39;id&#39;: &#39;1234&#39;,
&#39;name&#39;: &#39;谢**&#39;,
&#39;sex&#39;: True,
&#39;birthday&#39;: &#39;199* - 2&#39;
}
print(student1)
# 遍历字典中的键
for key in student1.keys():
print(key, student1[key])
print(&#39;-&#39; * 20)
# 遍历字典中的值
for value in student1.values():
print(value)
print(&#39;-&#39; * 20)
# 遍历字典中的键值对 ----> 相当于二元组
for key,value in student1.items():
print(key, value)
print(&#39;-&#39; * 20)
# 构造器函数
student2 = dict(id = 2345, name = &#39;小明&#39;, sex=True, birthday= &#39;1984 - 5&#39;)
print(student2)
# 生成式(推导式)语法
dict1 = {i: i ** 2 for i in range(1, 10)}
print(dict1)字典的运算:
字典的索引运算放在赋值运算符的左边,如果索引对应的键是存在的,就更新它的值,如果字典中没有对应的索引,就增加一组新的”键值对“。
通过get()函数通过key获取value时,如果key不存在,不会发生KeyError错误,而是得到一个None(空值)
删除键值对:del 操作
如果要使用下标(索引)运算,必须要保证键一定存在。
# 索引运算
student1 = dict(id=2345, name=&#39;小明&#39;, sex=True, birthday=&#39;1984 - 5&#39;)
student1[&#39;name&#39;] = &#39;小李&#39;
student1[&#39;address&#39;] = &#39;四川成都&#39;
student1[&#39;sex&#39;] = False
print(student1)
# 成员运算
print(&#39;name&#39; in student1)
print(&#39;age&#39; in student1)
print(&#39;address&#39; in student1)
# 通过get()函数通过key获取value时,如果key不存在,不会发生KeyError错误
# 而是得到一个None(空值)或者是被指定的默认值
print(student1.get(&#39;age&#39;)) # 默认得到一个空值
print(student1.get(&#39;age&#39;, 20)) # 不存在时输入指定的默认值20
print(student1.get(&#39;name&#39;, &#39;无名氏&#39;))
# 删除键值对
# del student1[&#39;name&#39;] # 用del操作删除name这个键值对,但是必须保证键存在,否则系统会出错
print(student1.pop(&#39;name&#39;)) # 也可以通过pop删除指定键值对,并显示所删除的值
print(student1.get(&#39;name&#39;, &#39;无名氏&#39;)) # 当name这个键不存在时不会报错,输出无名氏
# 如果要使用下标(索引)运算,必须要保证键一定存在,可以通过if语句判断再输出
if &#39;birthday&#39; in student1:
print(student1[&#39;birthday&#39;])字典的相关操作:
_.update()函数 ----> 更新字典,没有的加入,相同键更新值,也称元素的合并。
_.setdefault()函数-----> 键如果在字典中就返回原来的值,不会有任何改变,如果不在就加入新的键值对并返回给的值,如果没有给默认值,输出None
zip()函数-----> 把两组值压成一个二元组
max、min、sorted函数都有一个名为key的参数,改参数可以指定比较元素大小的规则
当key=len时,可以通过对元素指定len函数获得一个长度值来作为比大小的规则
&#34;&#34;&#34;
example04 - 字典中保存了股票信息,完成下面的操作
1. 找出股票价格大于100元的股票并创建一个新的字典
2. 找出价格最高和最低的股票对应的股票代码
3. 按照股票价格从高到低给股票代码排序
&#34;&#34;&#34;
stocks = {
&#39;AAPL&#39;: 191.88,
&#39;GOOG&#39;: 1186.96,
&#39;IBM&#39;: 149.24,
&#39;ORCL&#39;: 48.44,
&#39;ACN&#39;: 166.89,
&#39;FB&#39;: 208.09,
&#39;SYMC&#39;: 21.29
}
# stocks1 = {}
# for key,value in stocks.items():
# if value > 100:
# stocks1[key] = value
# print(stocks1)
# 找出股票价格大于100元的股票并创建一个新的字典
stocks1 = {key: value for key, value in stocks.items() if value > 100}
print(stocks1)
# print(max(zip(stocks.values(), stocks.keys()))[1])
# print(min(zip(stocks.values(), stocks.keys()))[1])
# zip_obj = zip(stocks.values(), stocks.keys())
# max_price, max_code = zip_obj
# print(max_code)
# 找出价格最高和最低的股票对应的股票代码
print(max(stocks, key=stocks.get))
print(min(stocks, key=stocks.get))
# 按照股票价格从高到低给股票代码排序
print(sorted(stocks, key=stocks.get, reverse=True)) # sorted() 从小到大排序,用reverse反转字典的应用:
JOSN
一种轻量级的数据交换格式
- 两个异构的系统之间交换数据最好的选择是交换纯文本(可以屏蔽系统和变成语言的差异)
- 纯文本应该是结构化或半结构化的纯文本(有一定的格式)
~ XML ------> extensible Markup Language -----> 可扩展标记语言
~ JSON -------> JavaScript Object Notation-----> 大多数网站和数据接口服务使用的数据格式
~ YAML ------> Yet Another Markup Language
- 如何将JSON格式的字符串转换成Python程序中的字典?
-----> jsion 模块 ---->loads函数
loads()函数----> 可以将JSON格式的数据转成Python中字典
- URL -----> Universal Resource Locator ----> 统一资源定位符
联网获取JSON 格式的数据并解析出需要的内容:
修改三方库的下载来源为国内的镜像网站 ----> pip config set global.index-url https://pypi.doubanio.com/simple
三方库 ----> requests ----> pip install requests
协议 -----> 通信双方需要遵守的会话的规则。
HTTP / HTTPS ----> 通过URL 访问网络资源的协议 -----> Hyper-Text Transfer Protocol (超文本传输协议)
请求(request) - 响应(response) |
|



 发表于 2022-9-23 15:07:35
发表于 2022-9-23 15:07:35

