|
|
关注“FightingCV”公众号
回复“AI”即可获得超100G人工智能的教程
点击进入→FightingCV交流群
转载自:AI科技评论
作者:Walid S.Saba
编译:Antonio
编辑:陈彩娴
美国东北大学体验式人工智能研究所的高级研究科学家 Walid S. Saba 从组合语义的角度出发,提出一个观点:深度学习无法构造一个可逆的组合语义,所以它无法实现可解释AI。
可解释AI(XAI)
随着深度神经网络 (DNN) 用于决定贷款批准、工作申请、批准法院保释等与人们利益息息相关或者一些生死攸关的决定(例如在高速公路上突然停车),去解释这些决定,而不仅仅是产生一个预测分数,是至关重要的。
可解释人工智能 (XAI) 的研究最近集中在反事实(counterfactual)例子的概念上。这个想法很简单:首先制造一些有预期输出的反事实样例并输入到原来的网络中;然后,读取隐层单元解释为什么网络会产生一些其他输出。更正式地说:
“返回分数 p 是因为变量 V 具有与其关联的值 (v1, v2, ...)。如果 V 具有值 (v′1 , v′2 , ...),并且所有其他变量保持不变, 分数 p' 会被返回。”
下面则是更加具体的一个例子:
“你被拒绝贷款是因为你的年收入是 30,000 英镑。如果你的收入是 45,000 英镑,你就会获得贷款。”
然而,一篇由Browne 和 Swift提出的论文[1] (以下简称 B&W)最近表明,反事实示例只是稍微更有意义的对抗性示例,这些示例是通过对输入执行小的且不可观察的扰动而产生的,从而导致网络对它们进行错误分类具有很高的自信度。
此外,反事实的例子「解释」了一些特征应该是什么才能得到正确的预测,但「没有打开黑匣子」;也就是说,没有解释算法是如何工作的。文章继续争辩说,反事实的例子并没有为可解释性提供解决方案,并且「没有语义就没有解释」。
事实上,文章甚至提出了更强有力的建议:
1)我们要么找到一种方法来提取假定存在于网络隐藏层中的语义,要么
2)承认我们失败。
而Walid S. Saba本人则对(1)持悲观态度,换句话说他遗憾地承认我们的失败,以下是他的理由。
Fodor 和 Pylyshyn 的「鬼魂」
虽然大众完全同意B&W的观点,即“没有语义就没有解释”,但解释深度神经网络中隐藏层表示的语义为深度学习系统产生令人满意的解释的希望之所以不能够实现,作者认为,原因正是出自三十多年前Fodor 和 Pylyshyn [2]中概述的原因。
图注:Jerry A. Fodor(左)和 Zenon Pylyshyn
Walid S. Saba接着论证到:在解释问题出在哪里之前,我们需要注意到,纯粹的外延模型(例如神经网络)不能对系统性(systematicity)和组合性(compositionality)进行建模,因为它们不承认具有可再衍生的句法和相应语义的符号结构。
因此,神经网络中的表示并不是真正与任何可解释的事物相对应的“符号”——而是分布的、相关的和连续的数值,它们本身并不意味着任何可以在概念上解释的东西。
用更简单的术语来说,神经网络中的子符号表示本身并不指代人类在概念上可以理解的任何事物(隐藏单元本身不能代表任何形而上学意义的对象)。相反,它是一组隐藏单元,它们通常共同代表一些显着特征(例如,猫的胡须)。
但这正是神经网络无法实现可解释性的原因,即因为几个隐藏特征的组合是不可确定的——一旦组合完成(通过一些线性组合函数),单个单元就会丢失(我们将在下面展示)。
可解释性是“反向推理”,DNN无法逆向推理
作者讨论过为什么 Fodor 和 Pylyshyn 得出的结论是 NN 不能对系统性(因此是可解释的)推论进行建模[2]。
在符号系统中,有定义明确的组合语义函数,它们根据成分的意义计算复合词的意义。但是这种组合是可逆的——
也就是说,人们总是可以得到产生该输出的(输入)组件,并且正是因为在符号系统中,人们可以访问一种“句法结构”,这一结构含有如何组装组件的地图。而这在 NN 中都并非如此。一旦向量(张量)在 NN 中组合,它们的分解就无法确定(向量(包括标量)可以分解的方式是无限的!)
为了说明为什么这是问题的核心,让我们考虑一下 B&W 提出的在 DNN 中提取语义以实现可解释性的建议。B&W 的建议是遵循以下原则:
输入图像被标记为“建筑”,因为通常激活轮毂盖的隐藏神经元 41435 的激活值为 0.32。如果隐藏神经元 41435 的激活值为 0.87,则输入图像将被标记为“汽车”。
要了解为什么这不会导致可解释性,只需注意要求神经元 41435 的激活为 0.87 是不够的。为简单起见,假设神经元 41435 只有两个输入,x1 和 x2。我们现在所拥有的如下图 1 所示:
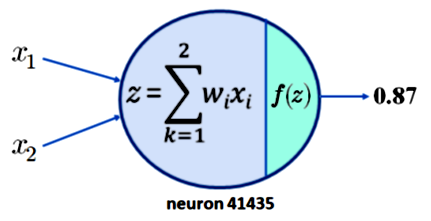
图注:拥有两个输入的单一神经元的输出为0.87
现在假设我们的激活函数 f 是流行的 ReLU 函数,那么可以产生 z = 0.87 的输出。这意味着对于下表中显示的 x1、x2、w1 和 w2 的值,可以得到 0.87 的输出。
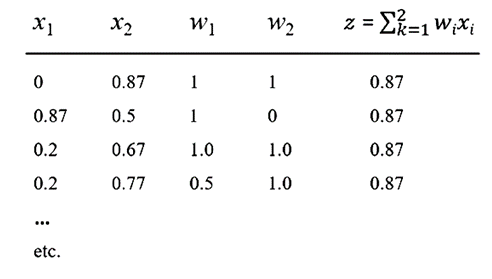
表注:多种输入方式都可以产生0.87的数值
查看上表,很容易看出 x1、x2、w1 和 w2 的线性组合有无数个,它们会产生输出 0.87。这里的重点是 NN 中的组合性是不可逆的,因此无法从任何神经元或任何神经元集合中捕获有意义的语义。
为了与 B&W 的口号“没有语义就没有解释”保持一致,我们声明永远无法从 NN 获得任何解释。简而言之,没有组合性就没有语义,没有语义就没有解释,DNN 无法对组合性进行建模。这可以形式化如下:
1. 没有语义就没有解释[1] 2. 没有可逆的组合性就没有语义[2]
3. DNN 中的组合性是不可逆的[2]
=> DNN 无法解释(没有 XAI)
结束。
顺便说一句,DNN 中的组合性是不可逆的这一事实除了无法产生可解释的预测之外还有其他后果,尤其是在需要更高层次推理的领域,如自然语言理解 (NLU)。
特别是,这样的系统确实无法解释一个孩子如何仅从 (<human> <likes> <entity>) 之类的模板中学习如何解释无限数量的句子,因为“约翰”、“邻居女孩”、 “总是穿着T恤来这里的男孩”等都是<human>的可能实例化,还有“经典摇滚”、“成名”、“玛丽的奶奶”、“在海滩上跑步”、 等都是 <entity> 的所有可能的实例。
因为这样的系统没有“记忆”,而且它们的组成不能颠倒,理论上它们需要无数个例子来学习这个简单的结构。【编者注:这一点正好是乔姆斯基对于结构主义语言学的质疑,并由此开启了影响语言学半个多世纪的转化生成语法。】
最后,作者强调,三十多年前Fodor 和 Pylyshyn [2]提出了对 NN 作为认知架构的批评——他们展示了为什么 NN 不能对系统性、生产力和组合性进行建模,所有这些都是谈论任何“语义”所必须的——而这一令人信服的批评从未得到完美的回答。
随着解决人工智能可解释性问题的需求变得至关重要,我们必须重新审视那篇经典论文,因为它显示了将统计模式识别等同于人工智能进步的局限性。
参考文献:
博客地址:https://cacm.acm.org/blogs/blog-cacm/264604-new-research-vindicates-fodor-and-pylyshyn-no-explainable-ai-without-structured-semantics/fulltext
[1] Browne, Kieran, and Ben Swift. &#34;Semantics and explanation: why counterfactual explanations produce adversarial examples in deep neural networks.&#34;arXiv preprint arXiv:2012.10076(2020). https://arxiv.org/abs/2012.10076
[2] Fodor, Jerry A., and Zenon W. Pylyshyn. &#34;Connectionism and cognitive architecture: A critical analysis.&#34;Cognition28.1-2 (1988): 3-71. https://uh.edu/~garson/F&P1.PDF
往期回顾
基础知识
【CV知识点汇总与解析】|损失函数篇
【CV知识点汇总与解析】|激活函数篇
【CV知识点汇总与解析】| optimizer和学习率篇
【CV知识点汇总与解析】| 正则化篇
【CV知识点汇总与解析】| 参数初始化篇
【CV知识点汇总与解析】| 卷积和池化篇 (超多图警告)
最新论文解析
ECCV2022 Oral | 微软提出UNICORN,统一文本生成与边框预测任务
NeurIPS 2022 | VideoMAE:南大&腾讯联合提出第一个视频版MAE框架,遮盖率达到90%
NeurIPS 2022 | 清华大学提出OrdinalCLIP,基于序数提示学习的语言引导有序回归
SlowFast Network:用于计算机视觉视频理解的双模CNN
WACV2022 | 一张图片只值五句话吗?UAB提出图像-文本匹配语义的新视角!
CVPR2022 | Attention机制是为了找最相关的item?中科大团队反其道而行之!
ECCV2022 Oral | SeqTR:一个简单而通用的 Visual Grounding网络
如何训练用于图像检索的Vision Transformer?Facebook研究员解决了这个问题!
ICLR22 Workshop | 用两个模型解决一个任务,意大利学者提出维基百科上的高效检索模型
See Finer, See More!腾讯&上交提出IVT,越看越精细,进行精细全面的跨模态对比!
MM2022|兼具低级和高级表征,百度提出利用显式高级语义增强视频文本检索
MM2022 | 用StyleGAN进行数据增强,真的太好用了
MM2022 | 在特征空间中的多模态数据增强方法
ECCV2022|港中文MM Lab证明Frozen的CLIP 模型是高效视频学习者
ECCV2022|只能11%的参数就能优于Swin,微软提出快速预训练蒸馏方法TinyViT
CVPR2022|比VinVL快一万倍!人大提出交互协同的双流视觉语言预训练模型COTS,又快又好!
CVPR2022 Oral|通过多尺度token聚合分流自注意力,代码已开源
CVPR Oral | 谷歌&斯坦福(李飞飞组)提出TIRG,用组合的文本和图像来进行图像检索 |
|



 发表于 2023-1-1 19:48:47
发表于 2023-1-1 19:48:47

