|
|
点击@CV计算机视觉,关注更多CV干货
简述:CNN和ViT都广泛应用于多任务学习(Multi-Task Learning,简称MTL)中,且各有优势。很多学者在研究多任务学习时,只使用CNN或者ViT中的一种架构。本文提出了一种新的多任务学习模型DeMT(Deformable Mixer Transformers),融合了Deformable CNN和ViT,用于密集预测(分割、深度估计、边缘检测等)的多任务学习。

- 论文:DeMT: Deformable Mixer Transformer for Multi-Task Learning of Dense Prediction
- 代码(即将开源):https://github.com/yangyangxu0/DeMT
- 单位:武汉大学、湖北珞珈实验室、京东探索研究院
1.动机
基于CNN的模型能更好地提取局部感受野的多任务特征,然而缺乏全局建模和任务间的通信;基于ViT的方法更关注全局特征,却忽略了任务特性(task awareness)且引入了较大的计算量。
作者提出Deformable Mixer Transformers(DeMT),DeMT融合了Deformable CNN和ViT的优势,能很好地应用于密集预测相关的多任务学习。
2.DeMT
2.1 整体结构
DeMT的整体结构如下图所示:
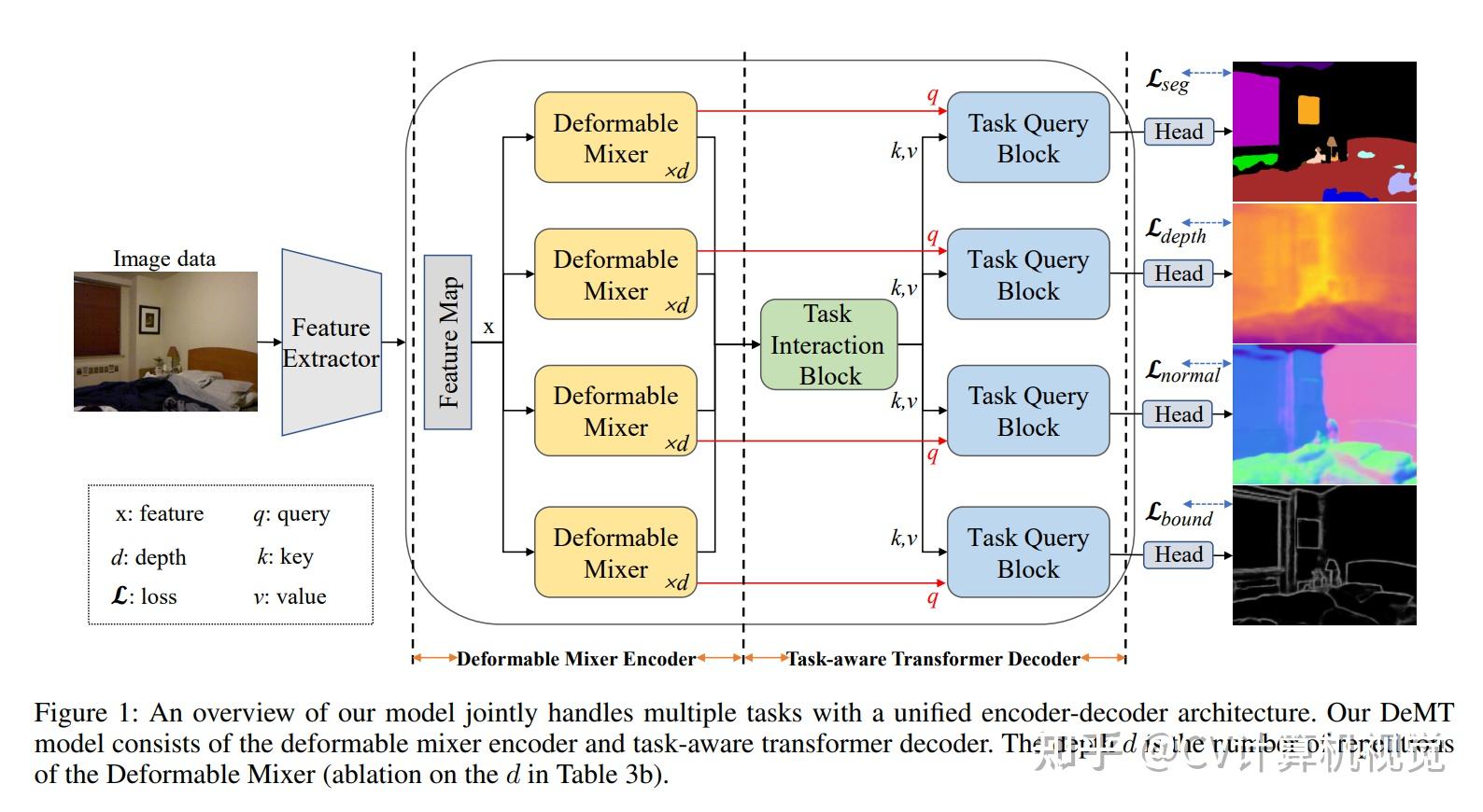
DeMT包含:
- 特征提取模块
- deformable mix encoder模块,对每个任务编码任务相关的空间特征
- task-aware transformer decoder模块,融合多个任务的特征,解码任务相关的特征
2.2 特征提取
每个任务共用特征提取网络,特征提取网络的输入为图像数据X_{i n} \in \mathbb{R}^{H \times W \times 3},H和W分别表示图像的高和宽。特征提取网络包含4个stage,对它们的输出进行upsample,保证尺寸相同,在通道维度进行拼接,拼接后特征的形状为X \in \mathbb{R}^{\frac{H}{4} \times \frac{W}{4} \times C}。
2.3 Deformable Mix Encoder
每个任务都有一个Deformable Mix Encoder模块,该模块将spatial-aware deformable spatial features和channel-aware location features进行分离。结构如下图黄色区域所示。
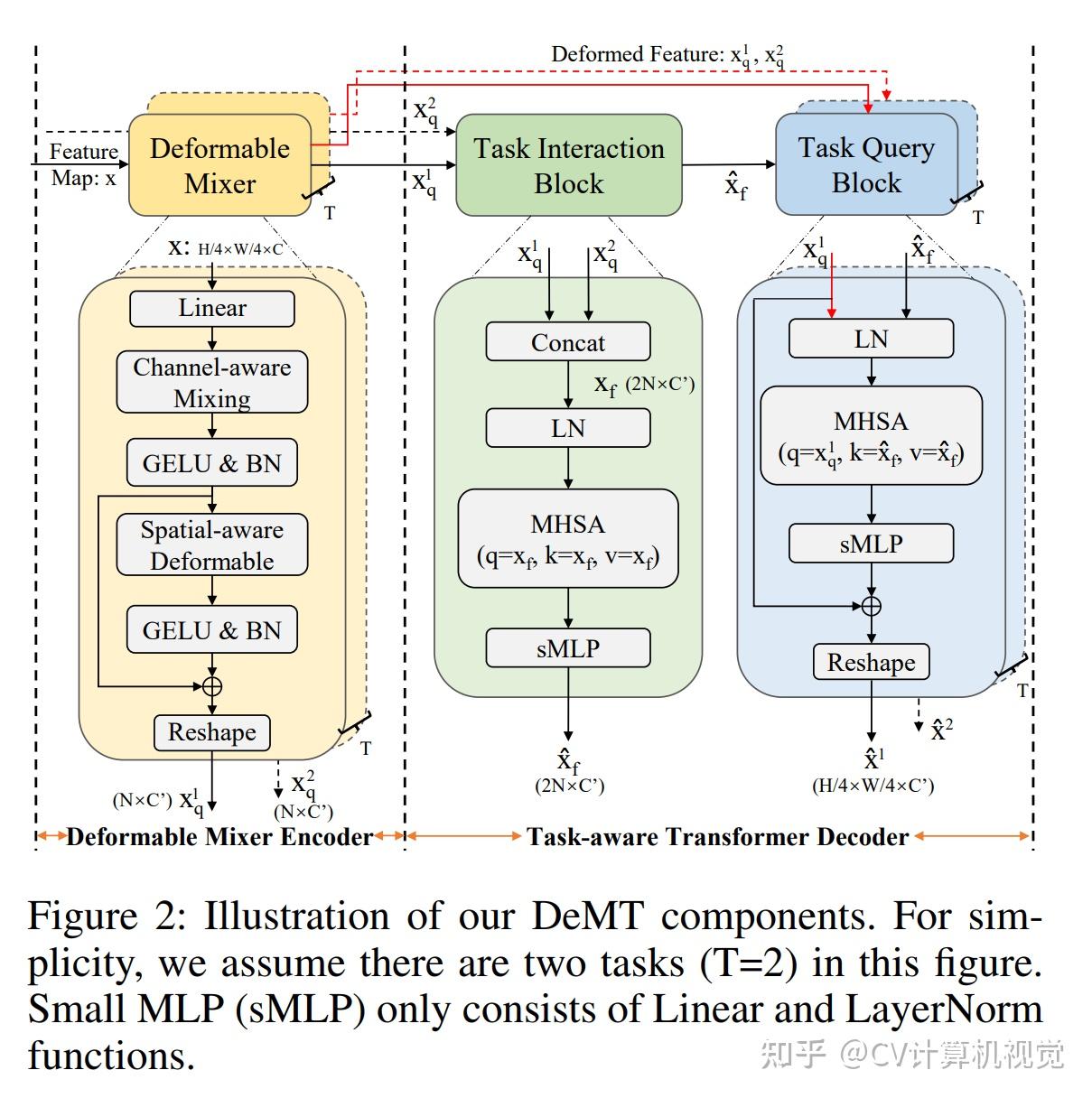
首先是1个包含LayerNorm的线性模块:X=W \cdot \operatorname{Norm}(X),该模块降将特征的维度C降低为C^{\prime}的输出为X \in\mathbb{R}^{\frac{H}{4} \times \frac{W}{4} \times C^{\prime}}。
然后是Channel-aware mixing模块,该模块使用1\times1卷积进行通道信息融合:X_{C^{\prime}}=\sum_{C^{\prime}=0}^{C^{\prime}-1} W_1 \cdot X_{C^{\prime}}+b
Channel-aware mixing的输出要经过GELU和BN:X_{C^{\prime}}=\operatorname{BN}\left(\sigma\left(X_{C^{\prime}}\right)\right),其中\sigma(\cdot)表示GELU。
紧接着是Spatial-aware deformable模块,为了产生参考点的相对偏移量,X_{C^{\prime}}首先进入CNN中得到相对偏移量\Delta_{(i, j)},紧接着计算spatial deformable操作:D_S\left(X_{i, j}\right)=\sum_{C^{\prime}=0}^{C^{\prime}-1} W_2 \cdot X\left((i, j)+\Delta_{(i, j)}, C^{\prime}\right)
最后是GELU、BN和Reshape操作:X_q=\operatorname{Reshape}\left(X_{C^{\prime}}+\operatorname{BN}\left(\sigma\left(D_S\left(X_{i, j}\right)\right)\right)\right)。Reshape操作将形状为X_q \in\mathbb{R}^{\frac{H}{4} \times \frac{W}{4} \times C^{\prime}}的特征转换为特征序列\mathbb{R}^{N \times C^{\prime}}\left(N=\frac{H}{4} \times \frac{W}{4}\right)。
假设有T个任务,则Deformable Mix Encoder的输出为\left(X_q^1, X_q^2, \cdots X_q^T\right)。
2.4 Task-aware Trsnformer Decoder
Task-aware Trsnformer Decoder包含Task interection block(上图绿色区域)和Task query block(上图蓝色区域)2部分。
首先对T个任务的特征进行通道维度的拼接:X_f=\operatorname{Concat}\left(X_q^1, X_q^2, \cdots X_q^T\right),得到拼接后的特征X_f \in \mathbb{R}^{T N \times C^{\prime}}。
然后构建了多头自注意力模块:
X_f^{\prime}=\operatorname{MHSA}\left(Q=\operatorname{LN}\left(X_f\right), K=\operatorname{LN}\left(X_f\right), V=\operatorname{LN}\left(X_f\right)\right)
\hat{X}_f=\operatorname{sMLP}\left(X_f^{\prime}\right)
\hat{X}_f \in \mathbb{R}^{T N \times C^{\prime}}是多任务融合的特征。LN表示LayerNorm,sMLP包含线性模块和LayerNorm。
构造了多头自注意力模块,其中X_q作为与任务相关的query,\hat{X}_f作为key和value。
首先对Q、K和V做LayerNorm: \hat{Q}=\operatorname{LN}\left(X_q\right), \quad \hat{K}=\operatorname{LN}\left(\hat{X}_f\right), \quad \hat{V}=\operatorname{LN}\left(\hat{X}_f\right)
然后进行MHSA操作:\hat{X}_q=\operatorname{MHSA}(\hat{Q}, \hat{K}, \hat{V})
最后是sMLP、残差连接和reshape操作:\hat{X}=\operatorname{Reshape}\left(X_q+\operatorname{sMLP}\left(\hat{X}_q\right)\right)。需要注意残差连接中的X_q来源于Task-aware Trsnformer Decoder。reshape操作将形状为\mathbb{R}^{N \times C^{\prime}}\left(N=\frac{H}{4} \times \frac{W}{4}\right)的特征转换为\hat{X} \in \mathbb{R}^{\frac{H}{4} \times \frac{W}{4} \times C^{\prime}}。
2.5 损失函数
多任务损失函数:\mathcal{L}_{\text {total }}=\sum_{t=1}^T \alpha_t \mathcal{L}_t,其中\mathcal{L}_t为任务t的损失函数, \alpha_t用于确定任务t的损失的贡献。
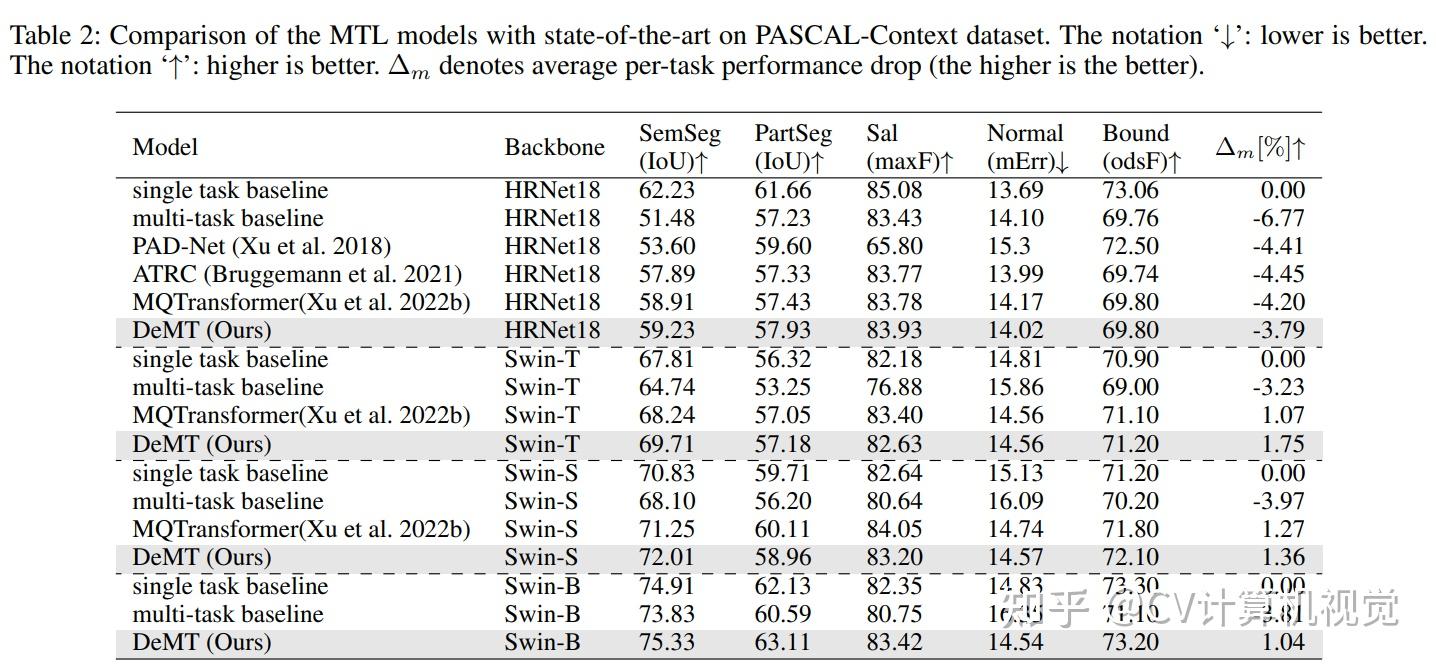
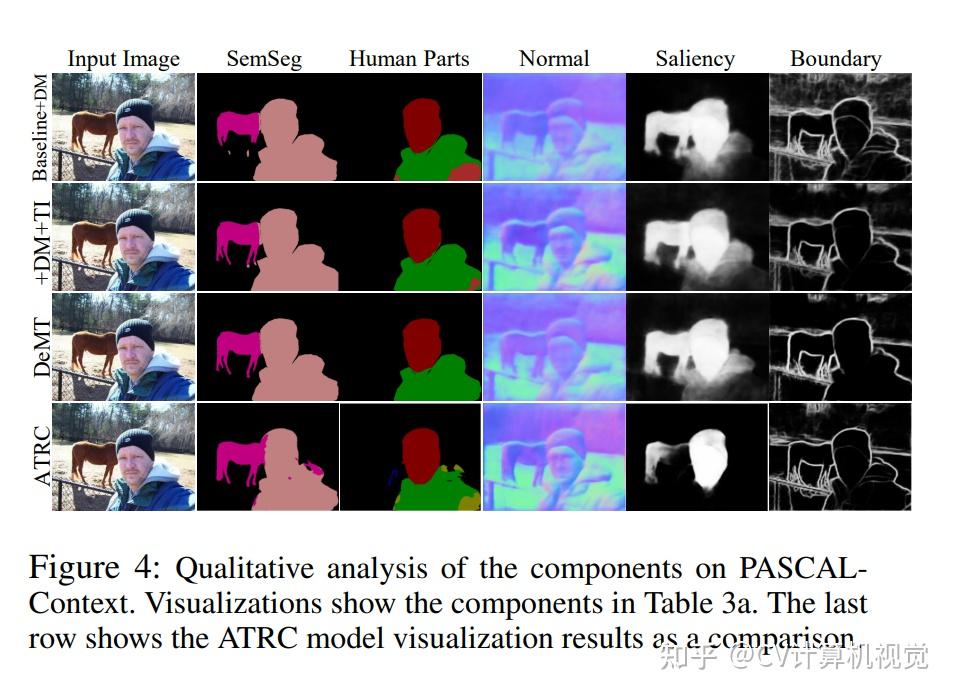
3.实验结果



推荐阅读: |
|



 发表于 2023-1-18 17:49:20
发表于 2023-1-18 17:49:20

