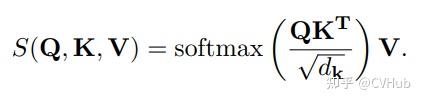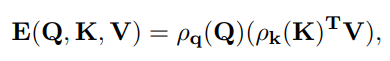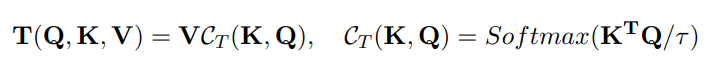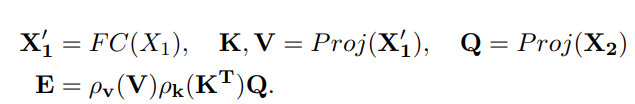2
5
7
新手上路
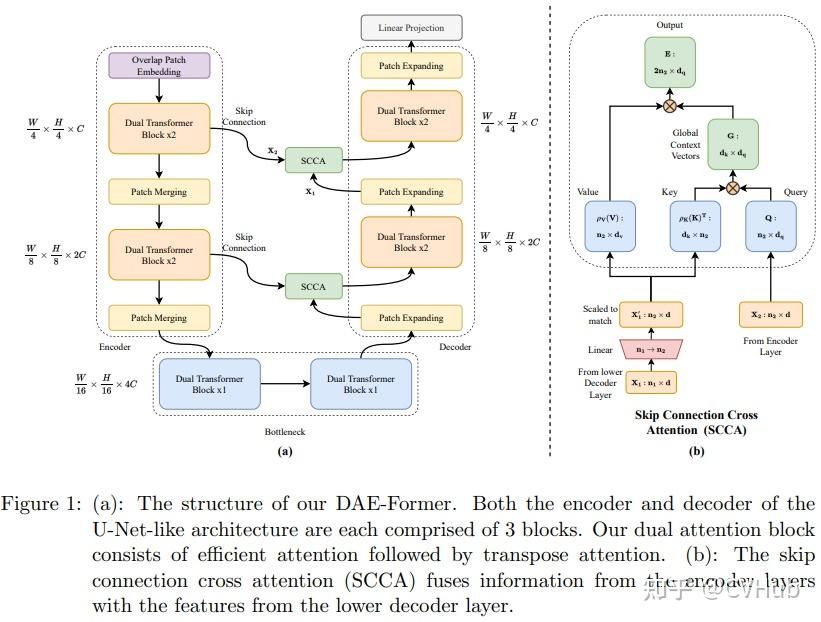
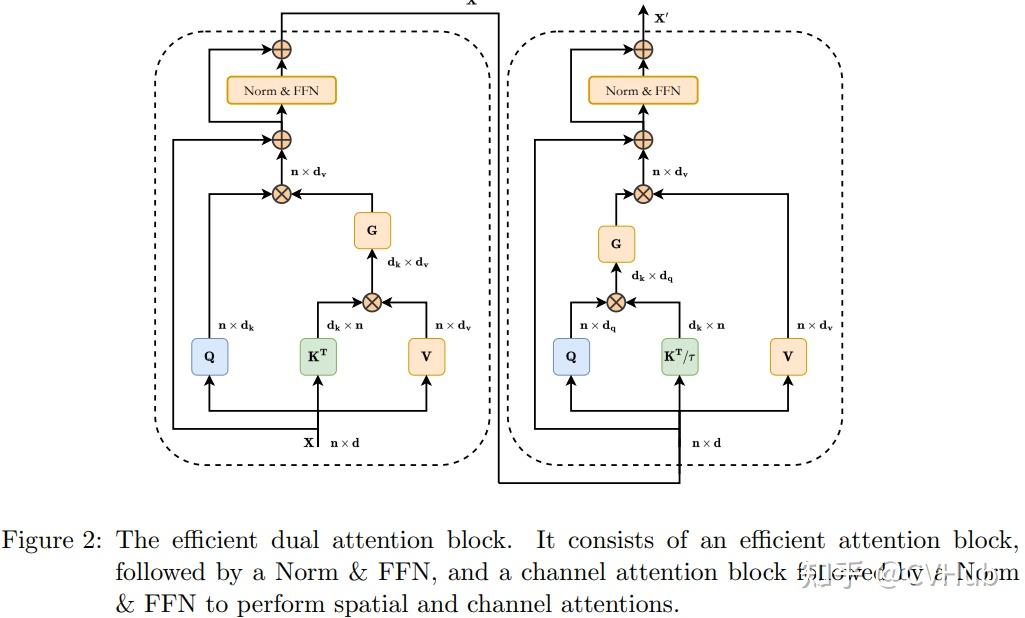
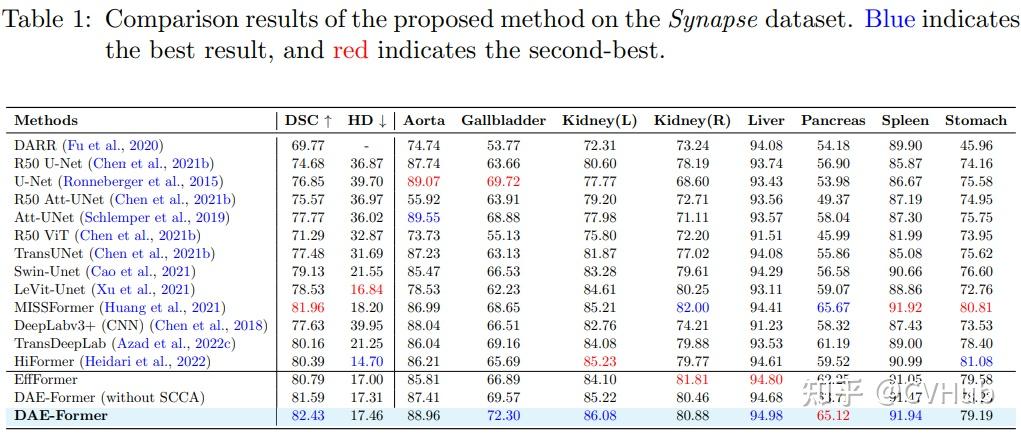
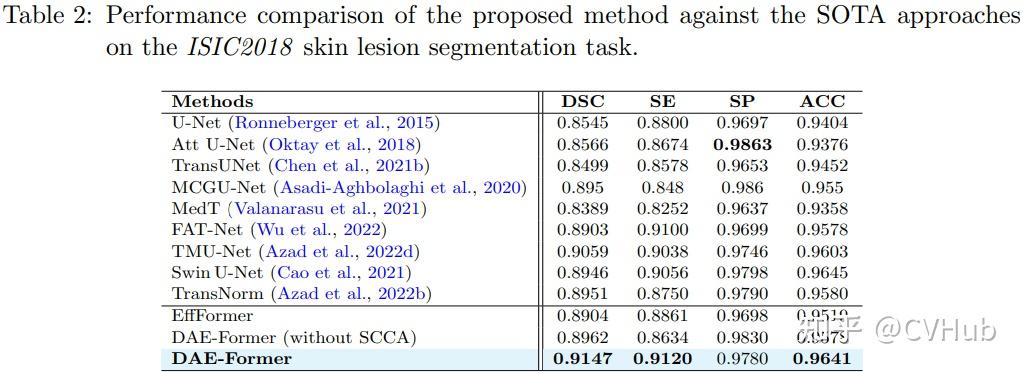
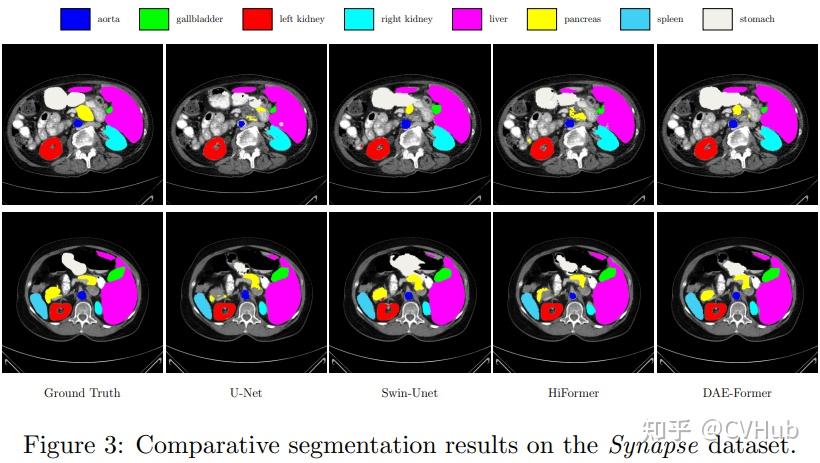
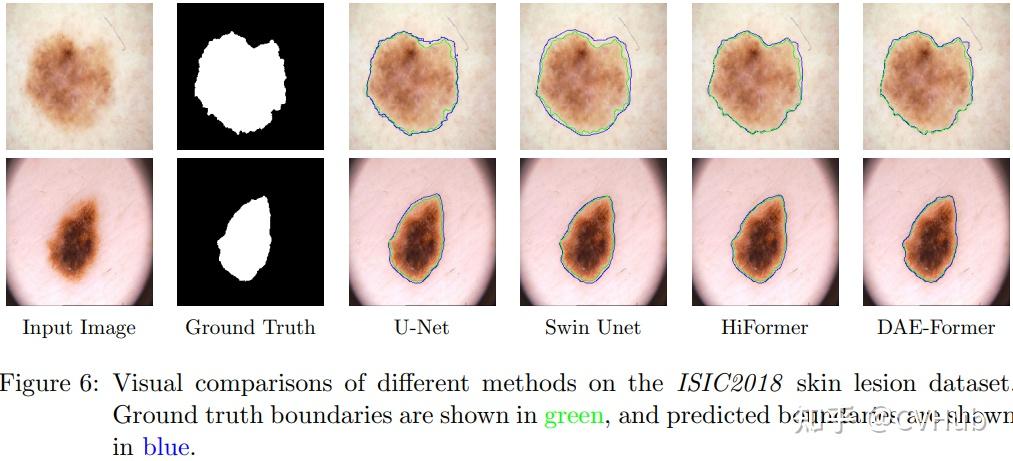
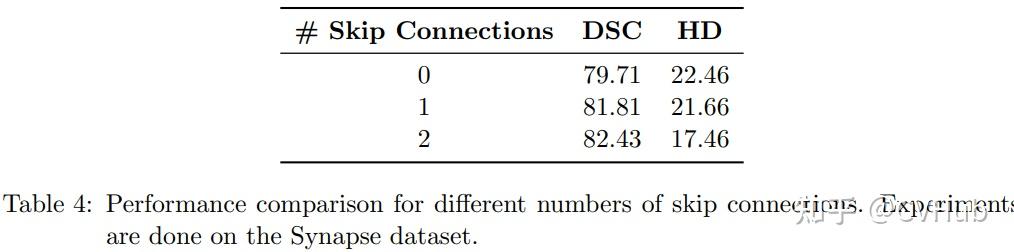
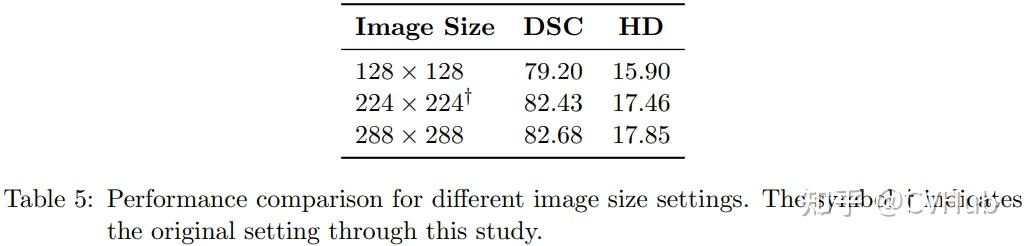
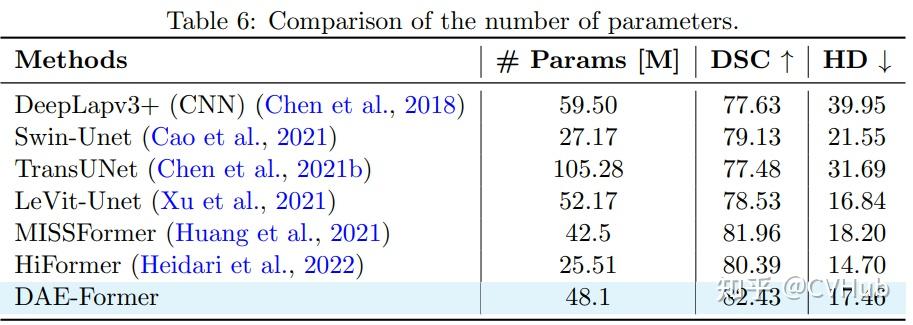
Title: DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation Author: Reza Azad et al. (亚琛工业大学) Paper: https://arxiv.org/pdf/2212.13504v1.pdf Github: https://github.com/mindflow-institue/daeformer
使用道具 举报
0
10
17
4
23
6
11
3
13
12
9
18
1
14
本版积分规则 发表回复 回帖后跳转到最后一页
云顶设计嘉兴有限公司模板设计.
免责声明:本站上数据均为演示站数据,如购买模板可以上DISCUZ应用中心购买,欢迎惠顾.
云顶官方站点:云顶设计 模板原创设计:云顶模板 Powered by Discuz! X3.4© 2001-2017 Comsenz Inc.



 发表于 2023-1-13 21:59:59
发表于 2023-1-13 21:59:59